
ディープラーニングを用いて3Dモーションデータを検索してみた!
機械学習グループのGANBAT NYAMKHUU(ガンバト ニャムフー)です。本記事では、私達が取り組んでいる3Dモーション検索の研究開発について紹介します。3Dモーションデータとは、3Dゲームのキャラクターがどのように動くかを指定するデータです。キャラクターは作っただけでは動きません。図1のような「走る」「剣を振る」といった1つ1つの動きをモーションデータとして作り込んでいくことで、キャラクターはゲーム世界をいきいきと動き回るようになります。

|

|

|

|

|
図1. モーションデータの例
それぞれのキャラクターに動きの数だけモーションデータが必要になります。そのため、1つのゲームに必要なモーションデータの数は、小規模なゲームでも何百種類、大規模なゲームでは何万種類にもなります。すべてを1から作っていては、高品質なモーションデータを大量に用意することはできません。クリエイターは新しいモーションデータを制作する際に、まず、既存のデータを探します。ピッタリのデータが見つかればそれを使うこともありますし、そうでない場合にも類似データを参考にしながら新しいモーションデータを制作することもあります。社内に眠る大量のモーションデータの中から素早く目的とするデータを見つけ出すために、機械学習グループは3Dモーション検索技術を研究開発しています。
以下に、私達が開発しているディープラーニングベースのアプローチを紹介します。まず、モーションデータがどのように表されているか説明し、次に、前処理によるキャラクターの位置や向きの正規化について説明します。最後に、私達のアプローチと検索例を紹介します。
モーションデータ
キャラクターのモーションを理解するためには、キャラクターのスケルトン(skeleton)とポーズ(pose)の概念を知っておく必要があります。スケルトン(図2)はキャラクターの形を表すデータ構造であり、関節(joint)とそれらを繋いだ骨(bone)から構成されます。
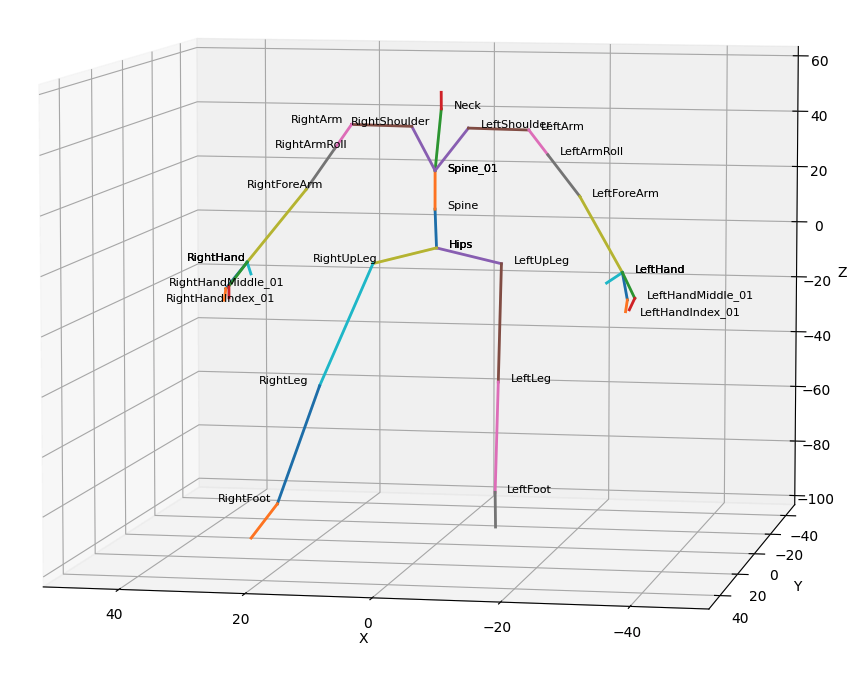
図2. スケルトンの構造
スケルトンは木構造をもっており、ノードは関節に、エッジは骨に対応します。まずrootノード(Hips)があり、そこから各関節が親子関係で表されます。子関節の位置(3D空間での座標)は親関節に対する平行移動、回転、拡大縮小の変換行列で表されます。
キャラクターのポーズは特定の時刻(フレーム)におけるスケルトンの状態を表します。 よって、キャラクターのモーションは各フレーム(時系列)におけるポーズで表すことができます。
|
|
|
|
|
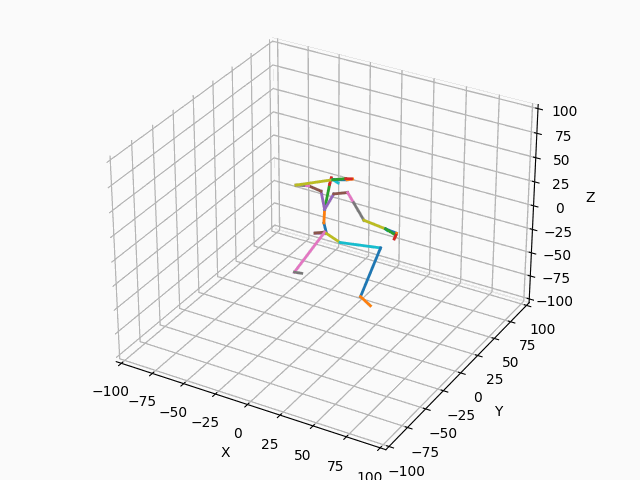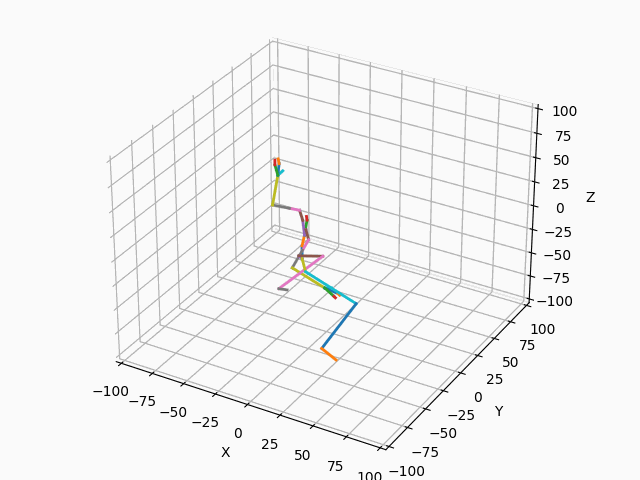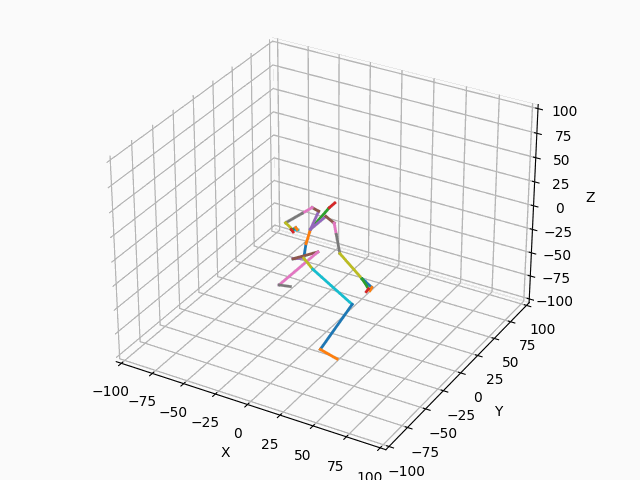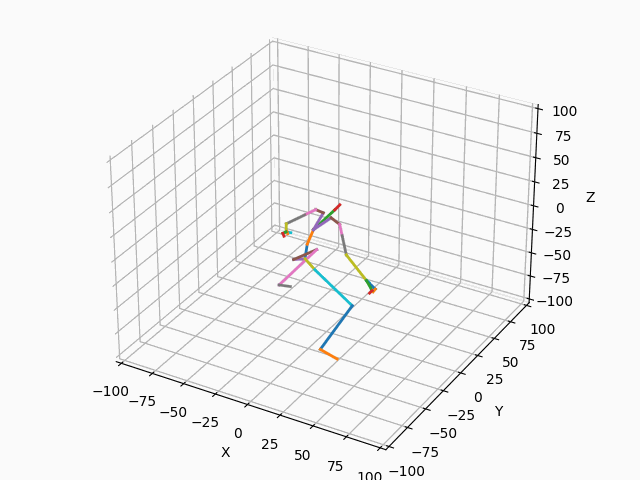 |
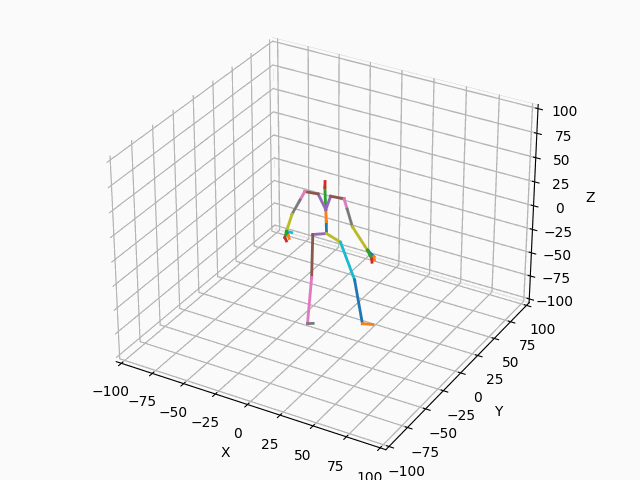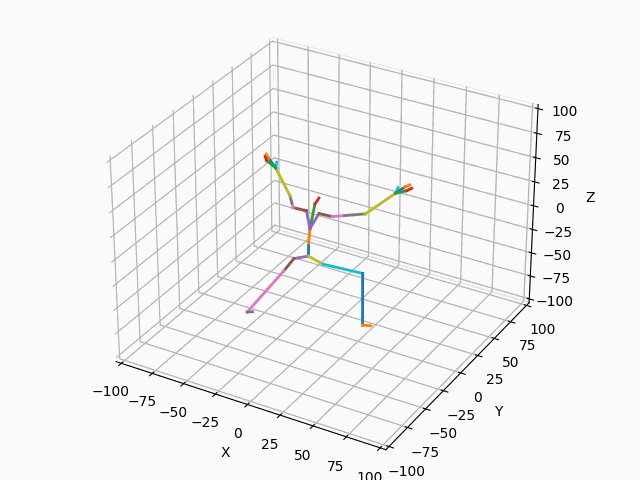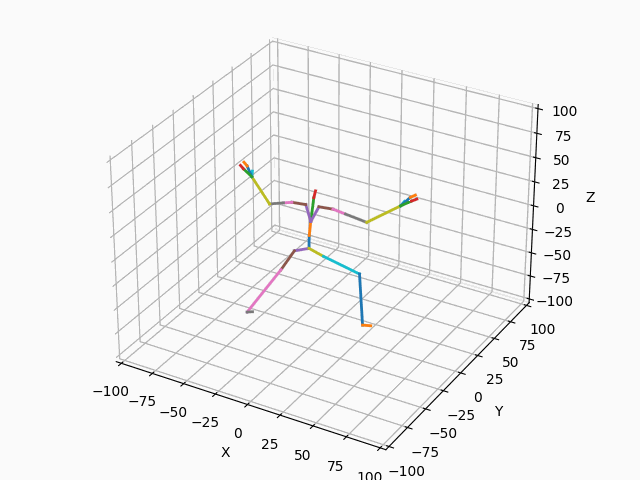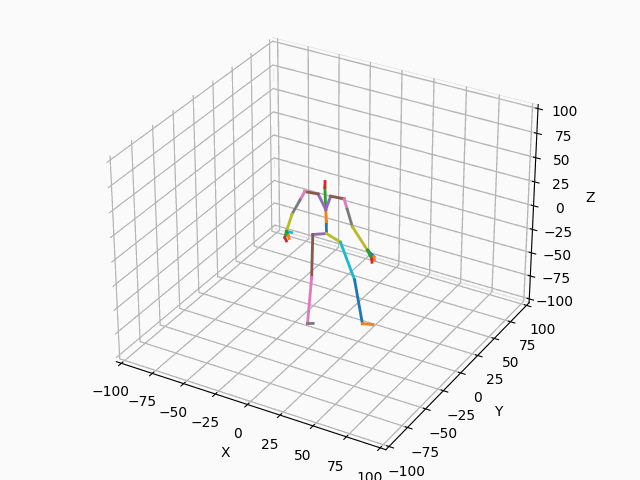 |
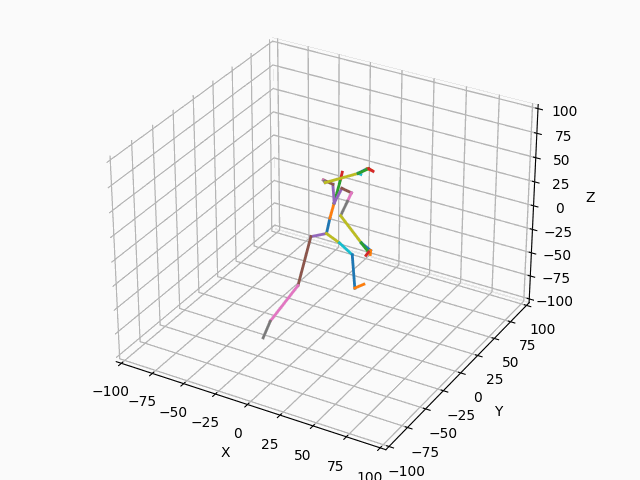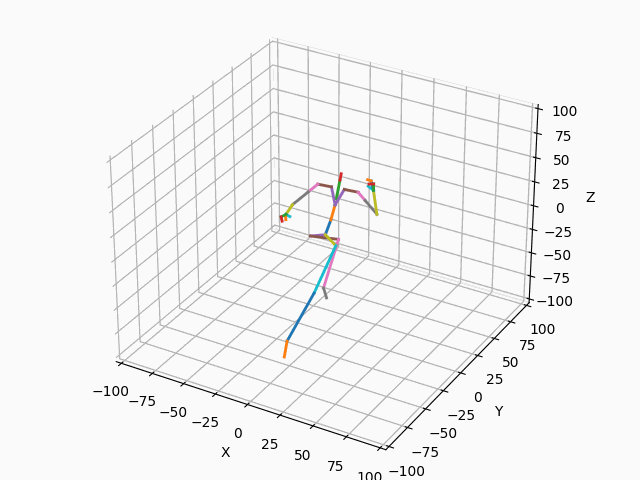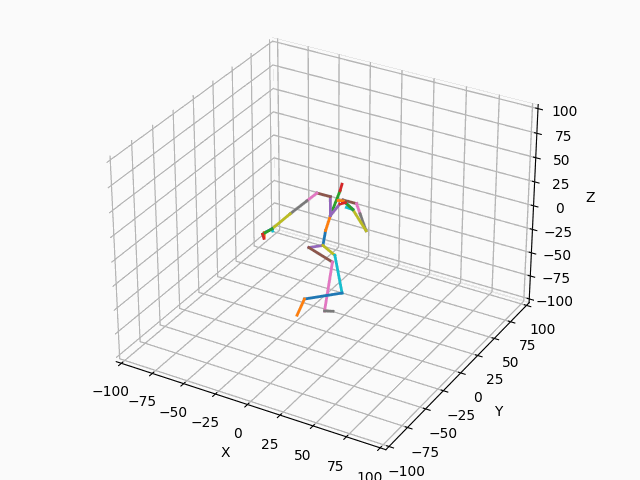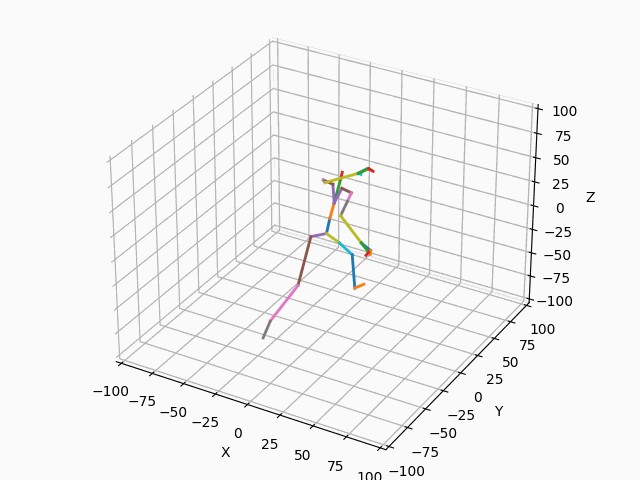 |
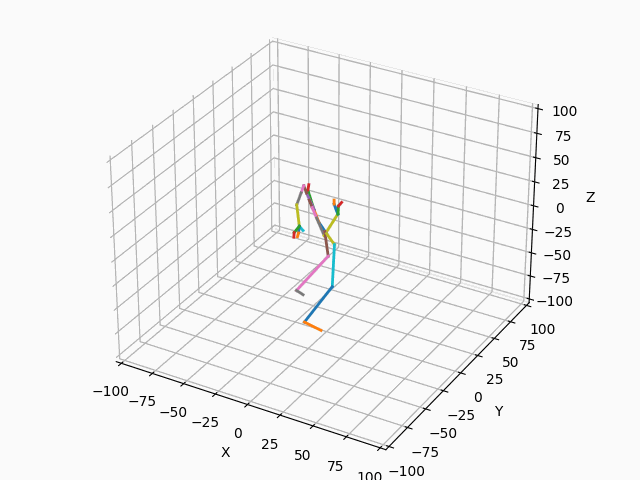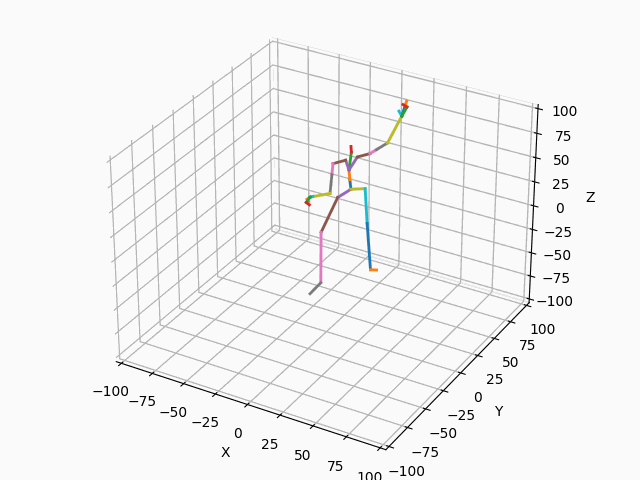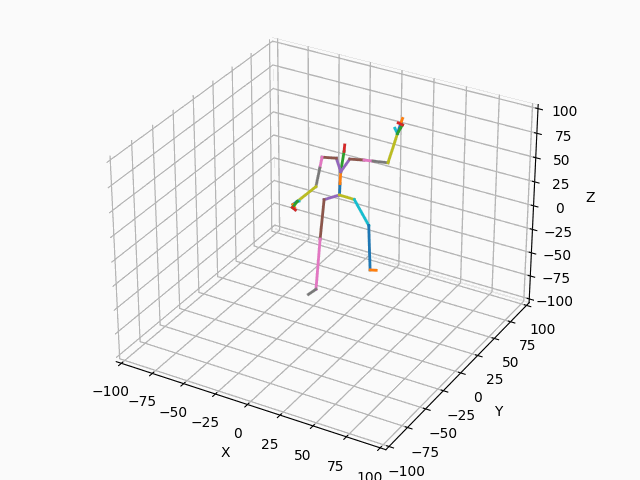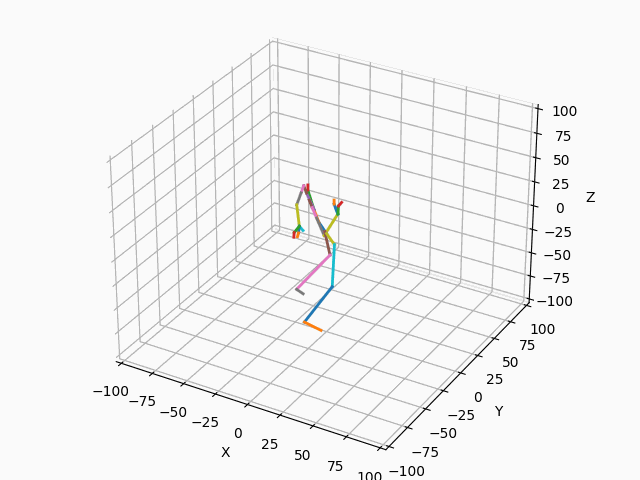 |
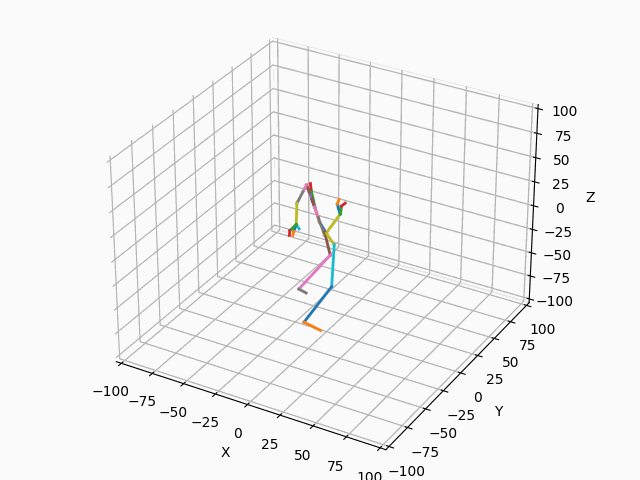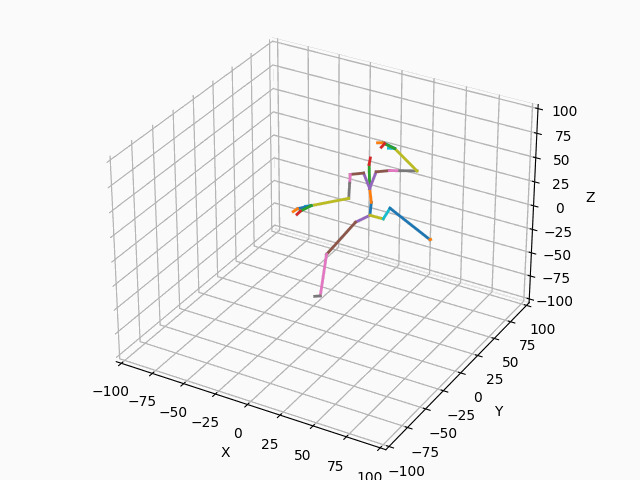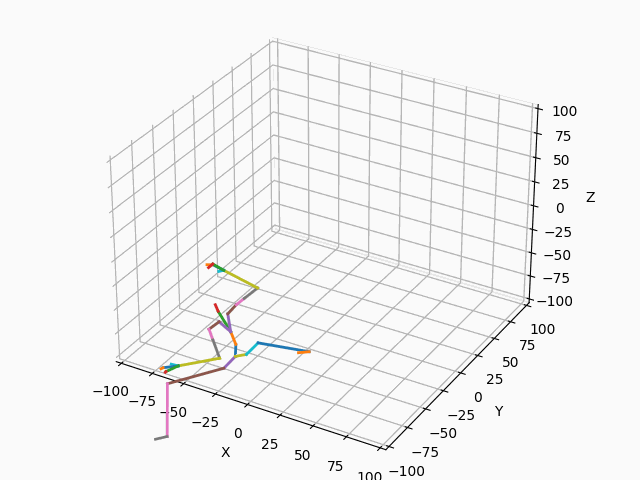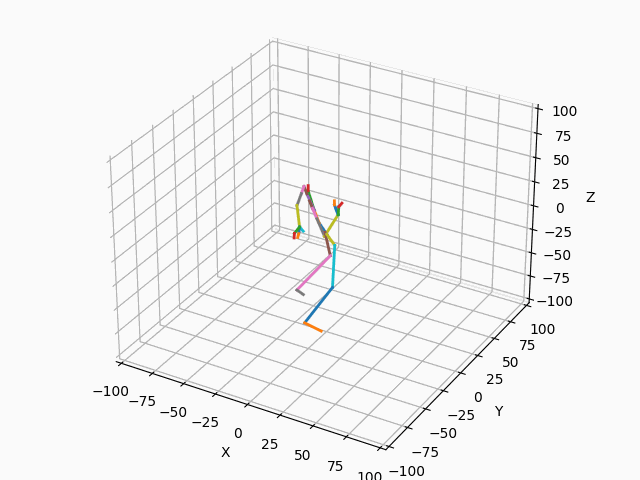 |
図3. スケルトンのモーション
正規化
2つのモーションの類似度を測るためにキャラクターの位置と向きを合わせる必要があります。また、異なる2つのキャラクターのモーションを比較する時にスケルトンのサイズを合わせる必要があります。ただし、今回の検証では同一のキャラクターのモーションデータを利用しているため、スケルトンのサイズについては正規化していません。
位置は以下の変換[1]によって正規化します。
- 最初のフレームにおけるポーズのrootノードを原点(0, 0, 0)に合わせる平行移動の行列を算出します。その行列を全てのフレームにおけるポーズに適用します。この正規化によって大ジャンプと小ジャンプのような同じポーズでありながら空間的に異なるモーションが区別できるようになると期待されます。
向きは以下の変換[1]によって正規化します。
- 最初のフレームにおけるポーズが常に特定の方向(図4ではY軸)に向くような回転行列を算出します。その行列を全てのフレームにおけるポーズに適用します。この正規化によりキャラクターの左回転と右回転などの対称なモーションを区別できるようになると期待されます。
以下の図4では正規化前と正規化後の例を示しています。
|
|
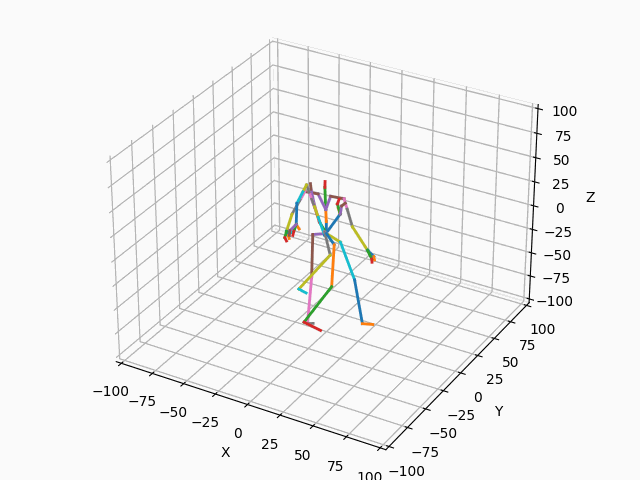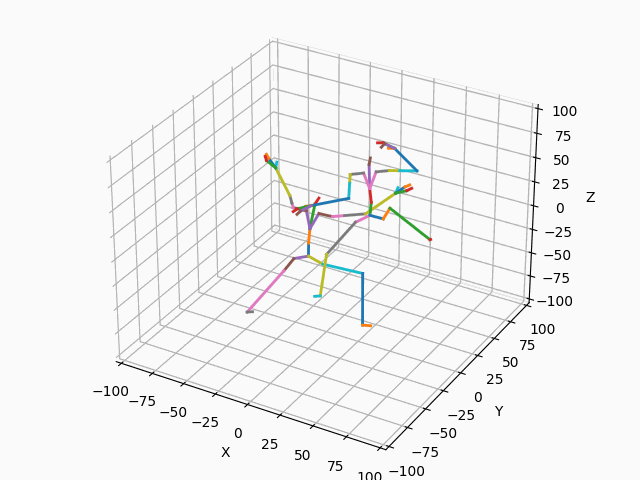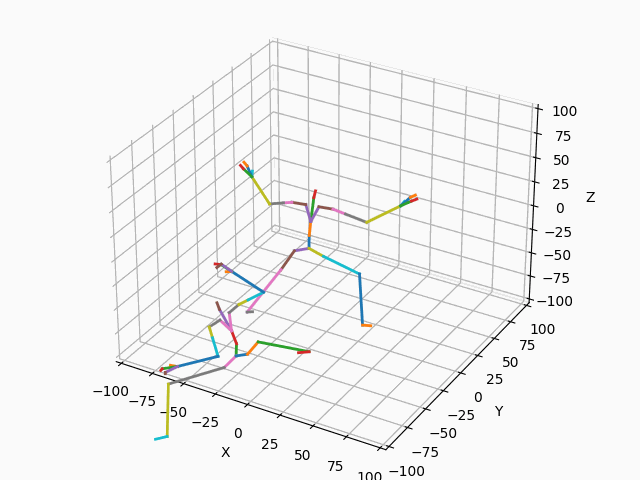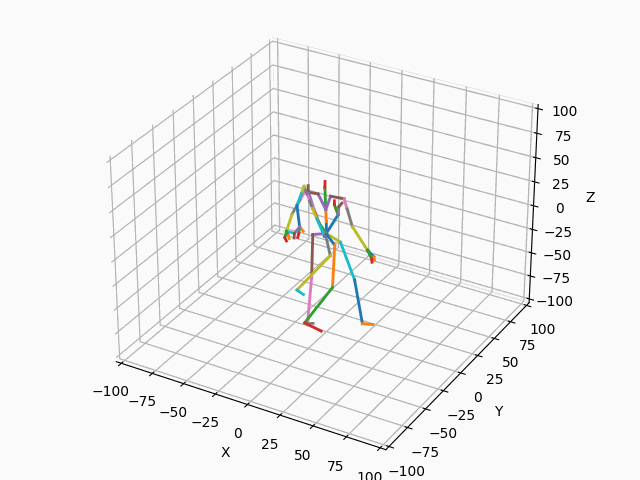
(b) 正規化後
図4. 正規化
図4aに示すように、正規化前の2つのモーションは開始位置や向きがバラバラです。図4bのように正規化して開始位置と向きを揃えることで、モーション間の差異を正しく測ることができるようになります。
アプローチ
ここでは、モーション検索に利用する特徴ベクトル(機械学習モデルの出力として得られる固定サイズのベクトル)の抽出と類似度算出について説明します。それぞれのモーションは長さ(フレーム数)が異なるため、モーションデータは可変長ベクトルになります。2つの可変長ベクトルを直接比較するのは困難です。そのため、機械学習を用いて可変長のモーションデータから固定サイズの特徴ベクトルを抽出し、2つのベクトルのユークリッド距離を類似度の指標とします。
固定サイズの特徴ベクトルを抽出するために、畳み込みニューラルネットワーク(CNN)を用いています。CNNは物体検出や画像分類などパターン認識のタスクにおいて高性能を示す定番の手法です。CNNを訓練するために、モーションデータにクラスラベルを付け、教師データとして用い、分類モデルを学習します。次に、学習済みのモデルの中間層から固定サイズの特徴ベクトルを抽出します。表1に学習に利用したデータのクラス毎のデータ数を示します。
表1. 学習データのクラスと各クラスのデータ数
| クラス | データ数 |
|---|---|
| Emotion | 21 |
| Attack | 6 |
| Idle | 32 |
| Skill | 289 |
| Other | 29 |
機械学習モデルの入力となるモーションデータ(各フレームの各Joint(関節)の空間位置(座標))の変換について説明します。物体検出や画像分類のタスクにおいて入力データは画像データになります。画像データは3階のテンソル(高さ、幅、色)で表されます。これと同様に、入力のモーションデータを3階のテンソル(最大フレーム数、関節数、座標)で表すことができます。画像の場合R、G、Bという色の3チャンネルになりますが、モーションデータの場合X、Y、Zという座標の3チャンネルになります。最大フレーム数は全データにおける最大のフレーム数になります。関節数はキャラクターのスケルトンの関節の数になります。すべてのデータを上記の固定サイズのテンソルに格納する必要があるため、フレーム数が短いモーションは最初のフレームを先頭にコピーして最大フレーム数に合わせました。
機械学習モデルの構造を図5に示します。今回の検証では学習データが少ないためパラメータが比較的少ない軽いモデルを採用しました。図5に示すように、4層の畳み込み層で特徴量を抽出し、そのあとFully Connected層を通して512次元の特徴ベクトルを抽出します。各畳み込み層の後にBatch Normalizationを適用し、活性化関数としてReLUを利用しました。
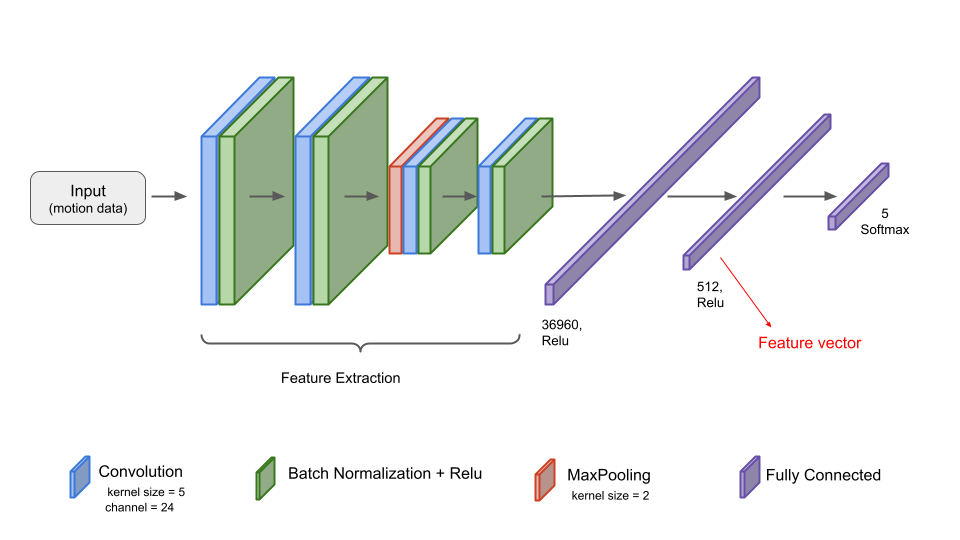 図5. モデルの構造
図5. モデルの構造
次に、クエリに使用するモーション(クエリモーション)に対する類似度算出について説明します。学習済みのモデルを利用して、各モーションデータに対する特徴ベクトルを抽出し、データベース化します。クエリモーションも同様に学習済みのモデルを用いて特徴ベクトルを抽出します。そのあと、データベースのベクトルとユークリッド距離を算出し、距離が小さいモーションから類似モーションとして出力します。
検索例
表2に、各クラスにおける検索例を示します。各クエリモーションに対して上位3つまで検索結果を表示しています。
表2. 検索例
| クラス | Emotion | Idle | Attack | Skill | Other |
|---|---|---|---|---|---|
| クエリモーション |  |
 |
 |
 |
 |
| 1位 |  |
 |
 |
 |
 |
| 2位 |  |
 |
 |
 |
 |
| 3位 |  |
 |
 |
 |
 |
どのクラスにおいてもクエリモーションと類似しているモーションが見つかっています。それぞれどこが類似しているか詳しくみていくと、Emotionの結果では手の動きに、Idleの結果ではキャラクターの姿勢に、Skillの結果ではジャンプしているモーションに、Otherでは走っているモーションに類似性が現れています。
このように、3Dモーション検索を利用することで、クリエイターはイメージに近いモーションを即座に見つけ出すことができるようになり、モーションデータのクオリティ向上により多くの時間を割けるようになると期待できます。今後の取組として、学習データを増やして検索の対象を広げる予定です。また、モデルに関しては一般的な物体検出などにおける学習済みのモデルを採用し、それをさらにfine-tuningすることでモデルの性能を向上させる予定です。
参考文献
[1] Sedmidubsky, Jan, Petr Elias, and Pavel Zezula. "Effective and efficient similarity searching in motion capture data." Multimedia Tools and Applications 77.10 (2018): 12073-12094.
このブログについて
KLabのゲーム開発・運用で培われた技術や挑戦とそのノウハウを発信します。
おすすめ
合わせて読みたい
このブログについて
KLabのゲーム開発・運用で培われた技術や挑戦とそのノウハウを発信します。