
DeepLearningで動画からモーションデータを作成! 「MocapNET」
機械学習グループの吉田です。
今回は機械学習で動画からモーションデータを自動で作成できるアルゴリズムMocapNETについて調査を行ったので、その内容を共有していきたいと思います。
MocapNETとは
MocapNETとは、DeepLearningを利用し動画データから人間の3Dモーションデータ(bvh)を作成する技術です。
この技術を利用すればモーションキャプチャのように特殊な機材を必要とすることなく動画データだけからモーションデータを作成することができます。
こちらが公開されているMocapNETの生成例です。ダンスの動画を使って左側に表示されているモーションのボーン情報を作成しています。

今回はこのMocapNETを使って、独自に動画からモーション情報を生成し3Dモデルに紐づけるまで行ってみましたので、その内容を共有します。
MocapNET アルゴリズム
MocapNETのアルゴリズムについて簡単に紹介します。
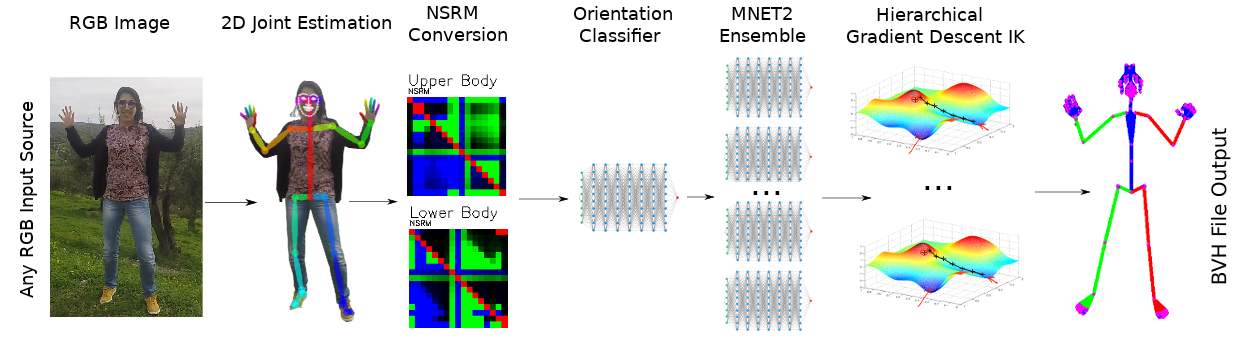
MocapNETの生成は大きく次のステップで行われます。
1. OpenPoseによる2Dポーズ検出
2. 2DポーズデータからNSRM マトリクスを生成
3. マトリクスを入力し向き(前後左右)を推定するNN
4. 向きに対応したNNで3Dポーズを推定
5. IK(Inverse Kinematics)の適用
1. OpenPoseによる2Dポーズ検出
まずRGB画像から2Dポーズ情報を推定します。この推定にはOpenPoseを利用しています。
2. 2DポーズデータからNSRMマトリクスを生成
ポーズ検出後、ユークリッド距離と似た考え方のNSRM(Normalized Signed Rotation Matrices) をポーズ各点の組み合わせに対して計算しマトリクスを作成します。
マトリクスは上半身と下半身に分けて2つを作成していきます。
3. マトリクスを入力し向き(前後左右)を推定するNN
作成したNSRMを入力とし、NN(Neural Network)を利用し向き(前後左右)の推定を行います。このNNの出力は4分類のOnehot表現として出力されます。
4. 向きに対応したNNで3Dポーズを推定
3で推定した向きに対応したNNを利用して3Dポーズ座標の推定を行っていきます。
このフェーズでもNNを利用し、BVH形式を表現するために必要な3D座標と3D角度を出力します。
5. IK(Inverse Kinematics)の適用
最後にIK(逆運動学)を利用してポーズ座標の整形を行っています。
実際に生成してみる
今回は以下2つのデータを利用して生成を行います。
- 公式サンプルのダンス動画
- 公式のGitHub上で公開されているサンプルデータです。こちらのYouTube動画 から最初の20秒をトリミングして利用しました。
- この動画での生成結果まで公式で公開されているので、動作が問題ないかの確認のために利用します。
- AIST dataset
- ストリートダンスの大規模データセット
- 今回はこの中の2動画を生成用として利用します。
生成フロー
1. MocapNET 環境構築
MocapNETのコードと学習済みモデルはGitHub 上に公開されています。
このコードを利用するための環境構築を行います。
環境構築の手順はReadMEに記載されているので、その通りに環境を構築していきます。(とはいってもReadME通りに問題なく環境構築できることは少ないので、適時対応します)
2. 動画ファイルからモーションデータ(bvh)を生成
環境構築が完了したので、公式サンプルのダンス動画を使って実際にモーションデータを生成していきます。
幸い、MocapNETは学習済みモデルまで公開されているので、スクリプト一つで生成を行うことが可能です。
動画からモーションデータを生成するスクリプト例は以下です。
$ ./MocapNET2LiveWebcamDemo --from /path/to/yourfile.mp4 --openpose
$ ./MocapNET2LiveWebcamDemo --from ../movie/samplevideo.mp4 --openpose
3. 公式サンプルの生成結果
生成したbvhファイルは以下となります。
オレンジ枠が今回生成したモーションデータ
もう片方が公式Gitで公開されている生成結果のサンプルとなります。
残念ながら手元で生成した結果と公式サンプルとは大きく乖離があり、手元で生成したものはモーションデータをまともに検出できていません。
4. 生成が不安定な原因の考察
GitHubには以下記載があります。
You should keep in mind that this OpenPose implementation does not use PAFs and so it is still not as precise as the official OpenPose implementation. OpenPoseはCMapというキーポイント(肘、肩など)を検出する役割をもったものと、PAFsといったキーポイント同士のつながりを表現する役割の2種類の特徴画像を用意するアルゴリズムですが、こちらの実装ではPAFsを利用していないため精度がでていなさそうです。
生成の精度を上げるために公式のOpenPoseの環境構築をしていきます。
5. OpenPoseの概要と環境構築
OpnePoseとは2D画像からポーズ情報を抽出するDeepLearningアルゴリズムです。

一見、OpenPoseを使えばMocapNETは必要ないようにも見えるかもしれませんが、OpenPoseは2Dのポーズ情報が抽出できるアルゴリズムのため、このままでは3Dモデルとは紐付けはできません。
OpenPoseで抽出した2Dのポーズ情報を3D情報に変換してあげるのがMocapNETの大きな役割となります。
OpenPoseのGitHub の記載に従い環境構築を行います。
6. OpenPoseからポーズ情報の生成
OpenPoseを利用してポーズ情報を生成します。
# ポーズ情報生成スクリプト例
$ build/examples/openpose/openpose.bin -number_people_max 1 --hand --write_json /path/to/outputJSONDirectory/ -video /path/to/yourVideoFile.mp4
実行が完了すると指定したパス内に以下のようにずらっとjsonのポーズ情報ファイルが作成されていることが確認できます。
$ ls
samplevideo_000000000000_keypoints.json samplevideo_000000000300_keypoints.json
samplevideo_000000000001_keypoints.json samplevideo_000000000301_keypoints.json
samplevideo_000000000002_keypoints.json samplevideo_000000000302_keypoints.json
samplevideo_000000000003_keypoints.json samplevideo_000000000303_keypoints.json
samplevideo_000000000004_keypoints.json samplevideo_000000000304_keypoints.json
samplevideo_000000000005_keypoints.json samplevideo_000000000305_keypoints.json
samplevideo_000000000006_keypoints.json samplevideo_000000000306_keypoints.json
samplevideo_000000000007_keypoints.json samplevideo_000000000307_keypoints.json
...
7. ポーズ情報ファイルからMocapNETでモーション情報(bvh)の生成
生成したjsonのポーズ情報を使って3Dモーションデータ(bvh)の生成を行います。
# jsonをCSVに変換
./convertOpenPoseJSONToCSV --from /path/to/outputJSONDirectory/ --label yourVideoFile --seriallength 12 --size 1920 1080 -o .
# CSVからモーションデータを生成
./MocapNET2CSV --from dataset/sample.csv --visualize --delay 30
以上で生成は完了です。生成結果としてbvhファイルが出力されています。
8. 公式サンプルの生成結果2
生成結果の動画が以下となります。
引き続きオレンジ枠が手元での生成結果、もう一方が公式サンプルの動画となります。
今度は大きな差分もなく、動作も問題なく生成できていそうです。
ここまでの結果をみているとMocapNETでは2Dポーズ検出の精度が3Dポーズ生成の精度にも大きく寄与しそうなことがわかります。(当たり前といえば当たり前ですが
9. AISTデータセット動画での生成
公式サンプルで動作の保証が取れたので、今度はAISTデータセットを使って生成してみたいと思います。
生成の手順自体は変わらないので割愛します。
2つの動画で試してみました。
動画①生成元
動画①生成結果
動画②生成元
動画②生成結果
まずまずの精度でモーションデータを生成できていそうです。
ただ、現状のボーンだけ表示させている状態ではわかりにくいところもあるので、次に3Dモデルとの紐付けを行っていきたいと思います。
3Dモデルとの紐付け
Blender を利用して生成したbvhファイルと3Dモデルの紐付けを行っていきます。
3Dモデルとの紐付けに関しては機械学習と関係のない3D関連の知識の話になります。自分は3Dに関してはあまり詳しくないため、色々雑だったり間違ってたりする箇所があるかもしれませんが、その点ご了承ください。
3Dモデルの準備
今回利用する3Dモデルはこちら のサイトからダウンロードしました。
なお、PCスペックと自分の能力不足によりテクスチャは利用しません。
3Dモデルとモーション情報(bvh)の紐付け
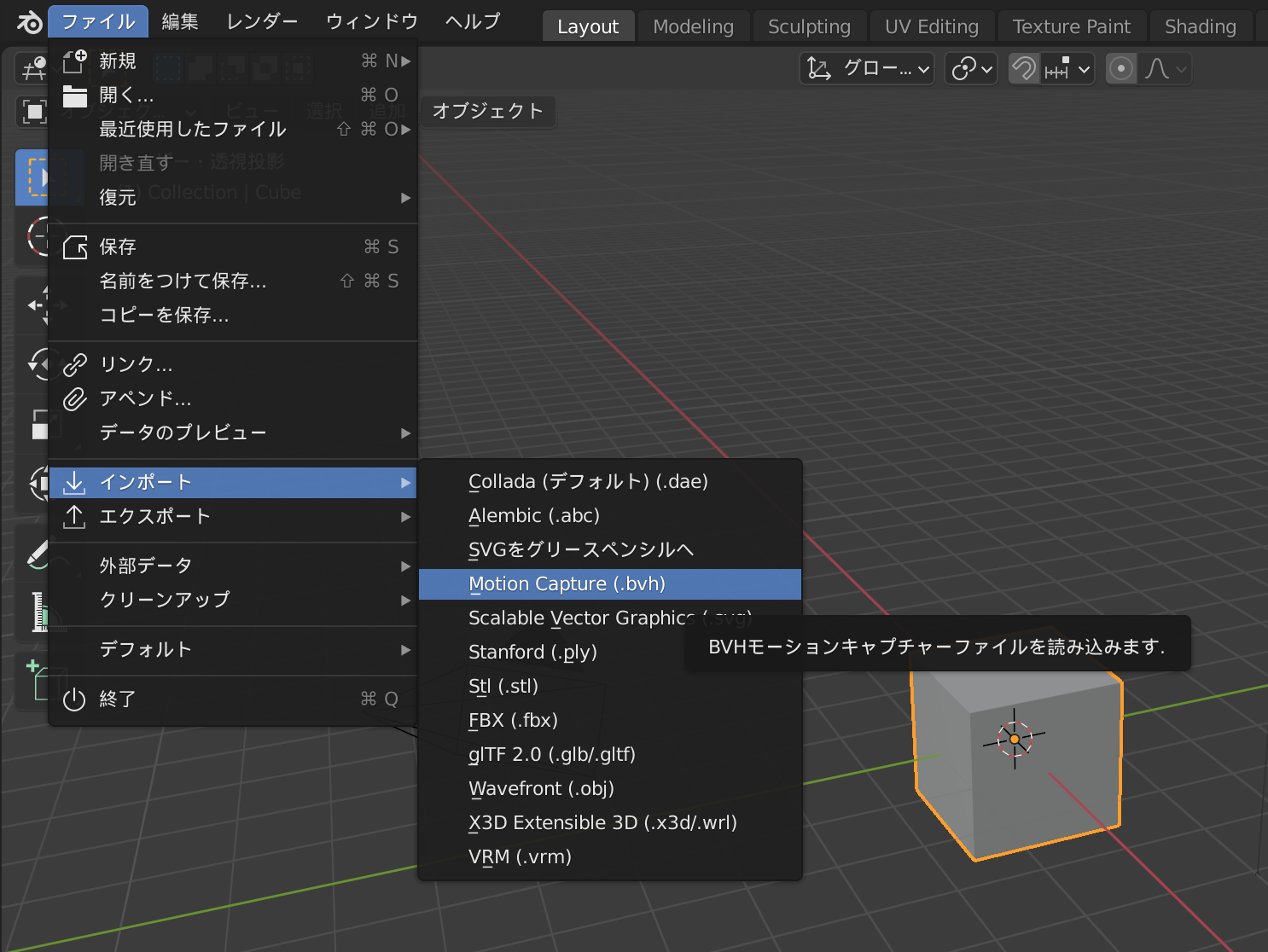
1. Blenderでモーションデータ.bvhをインポートする
ファイル→インポートからbvh形式を選択し、生成したbvhファイルをインポートします。
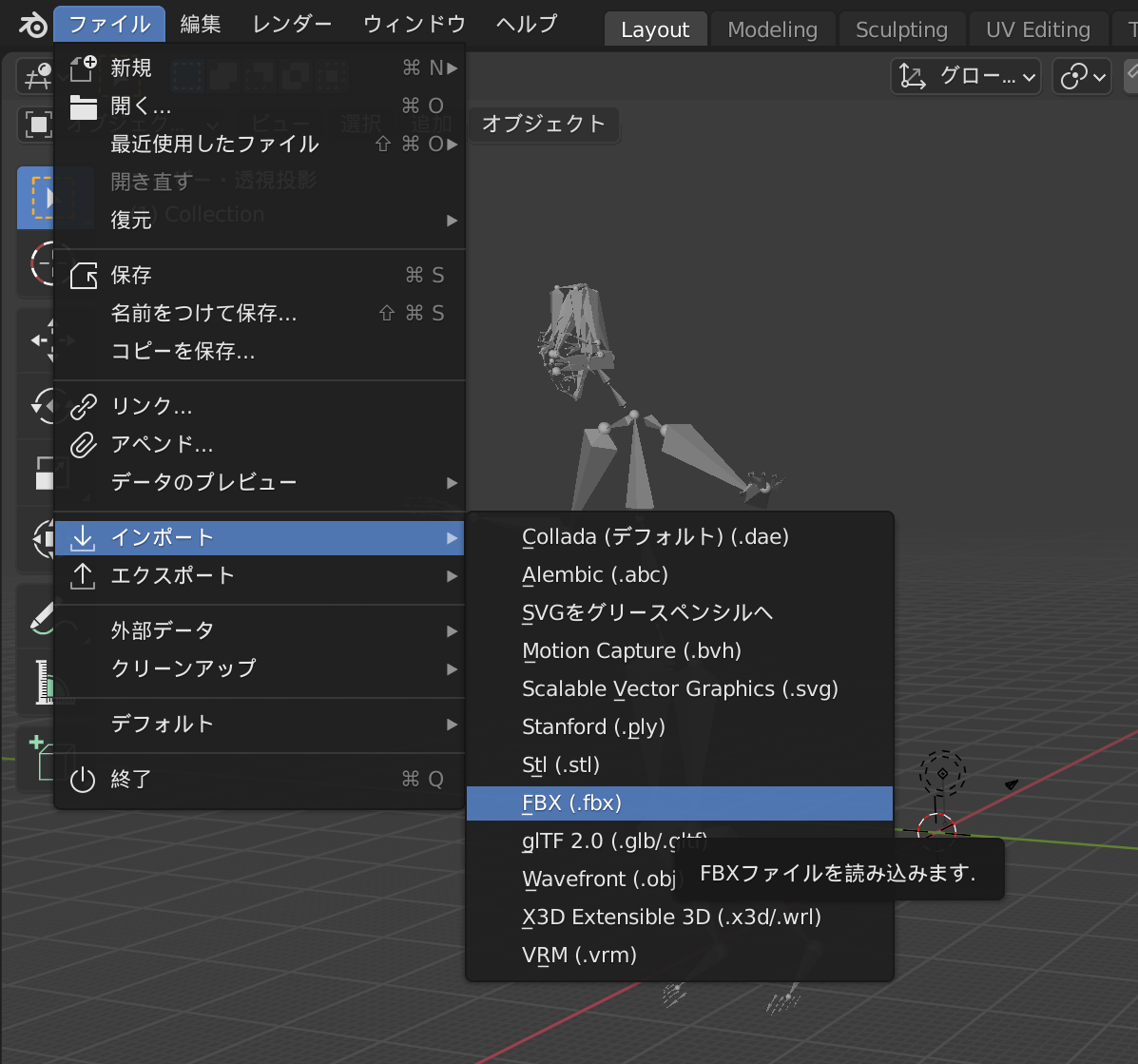
2. 3Dモデルデータをインポート
同様の手順で3Dモデルファイル(今回は.fbx)をインポートします。
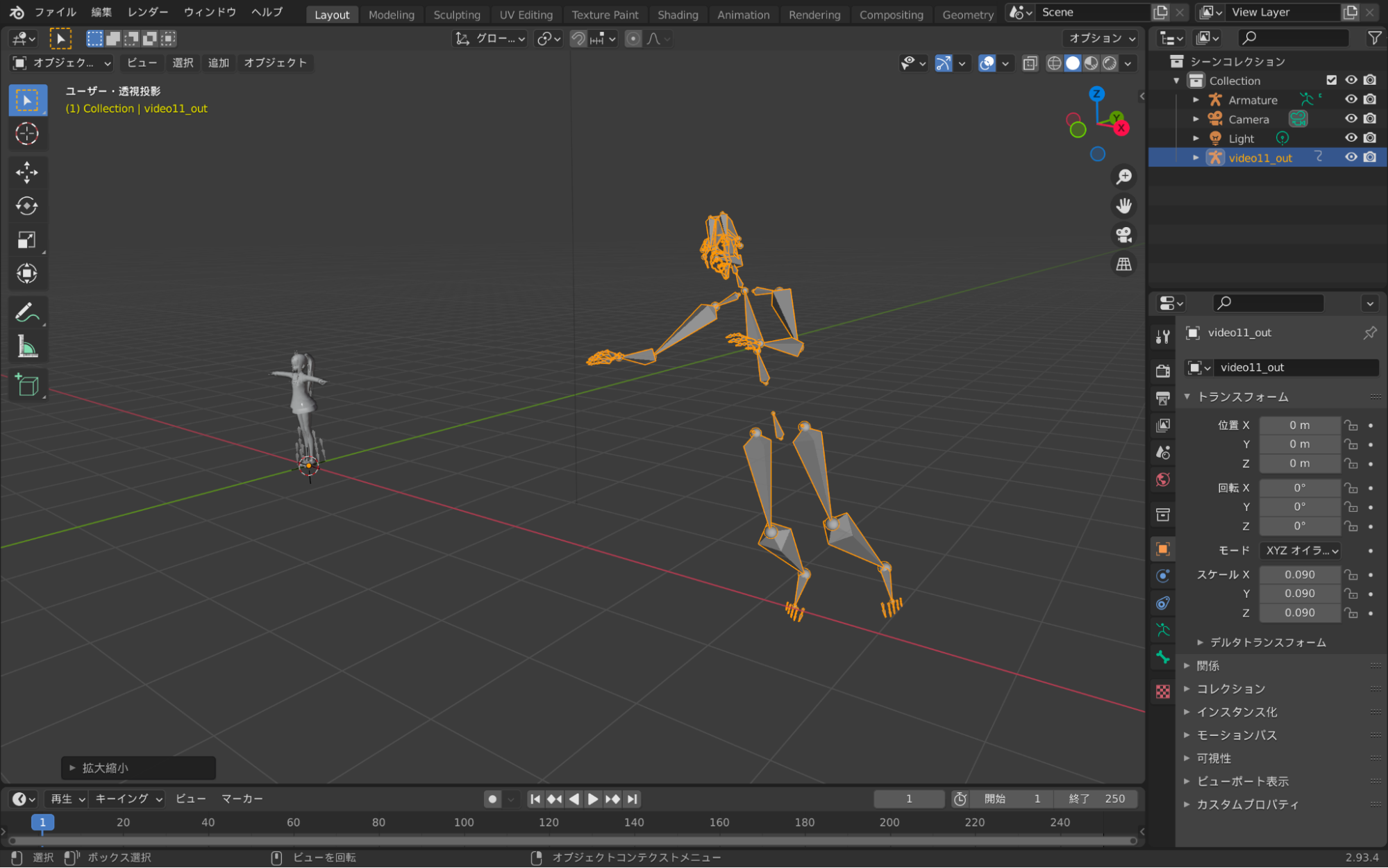
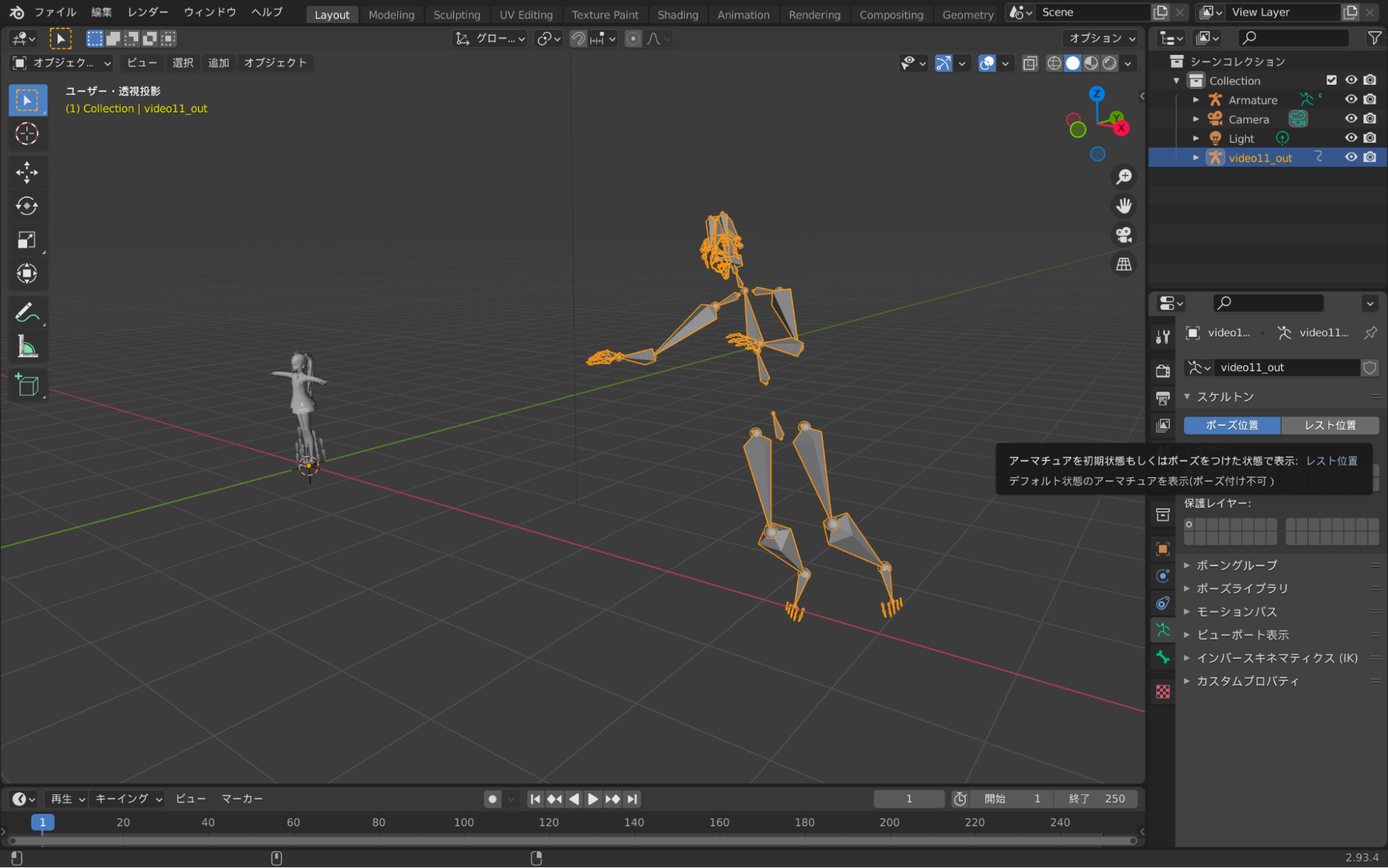
3. ボーンモデルをレスト状態にする
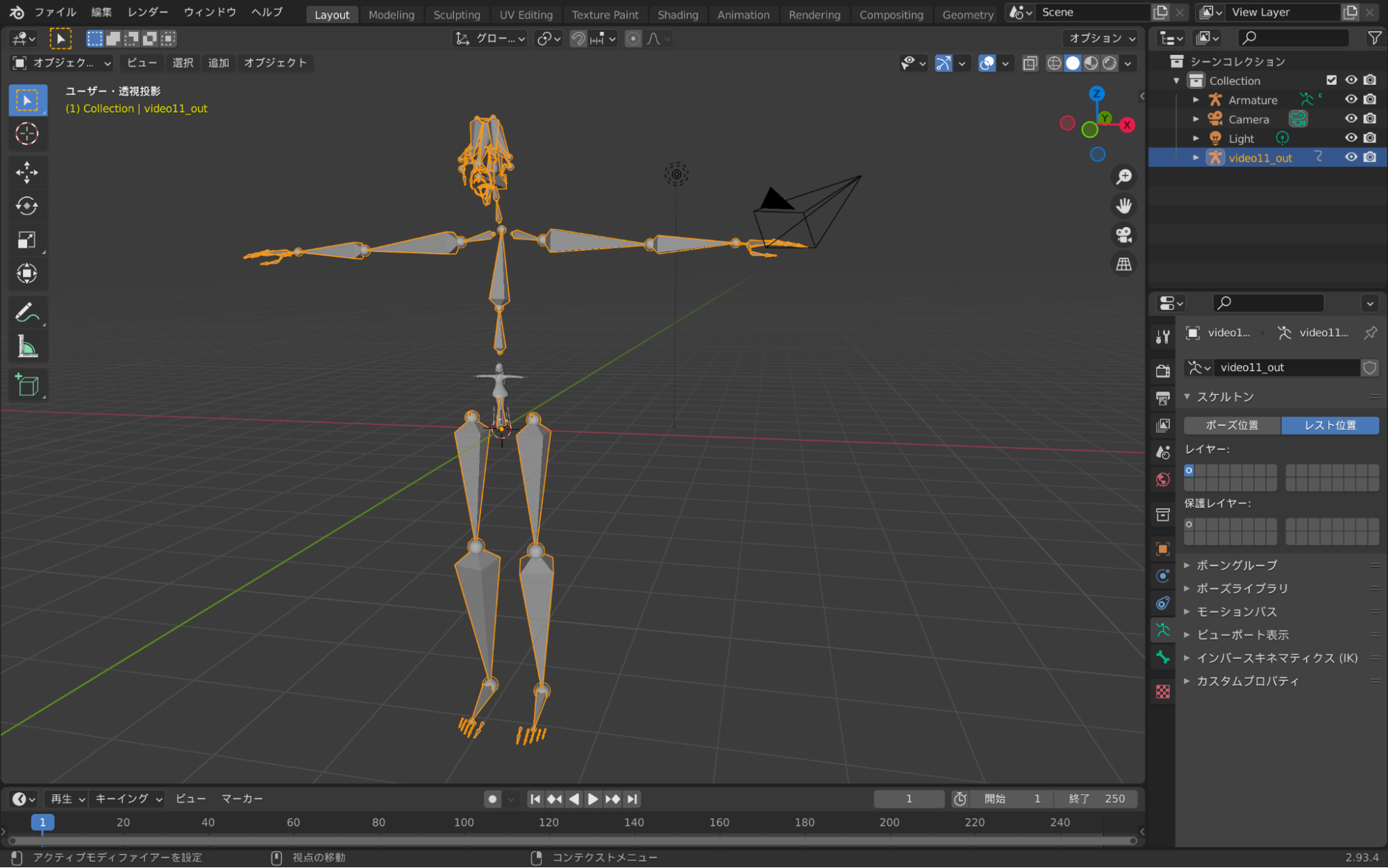
3Dモデルと紐付けを行う準備として、ボーンモデルをレスト状態にします。
レスト状態になるとボーンが手を横に広げた形になります。
4. ボーンと3Dモデルのサイズと位置を合わせる
インポートしただけの状態ではサイズ感などにかなり差があるためボーンと3Dモデルのサイズや位置を手動で合わせていきます。
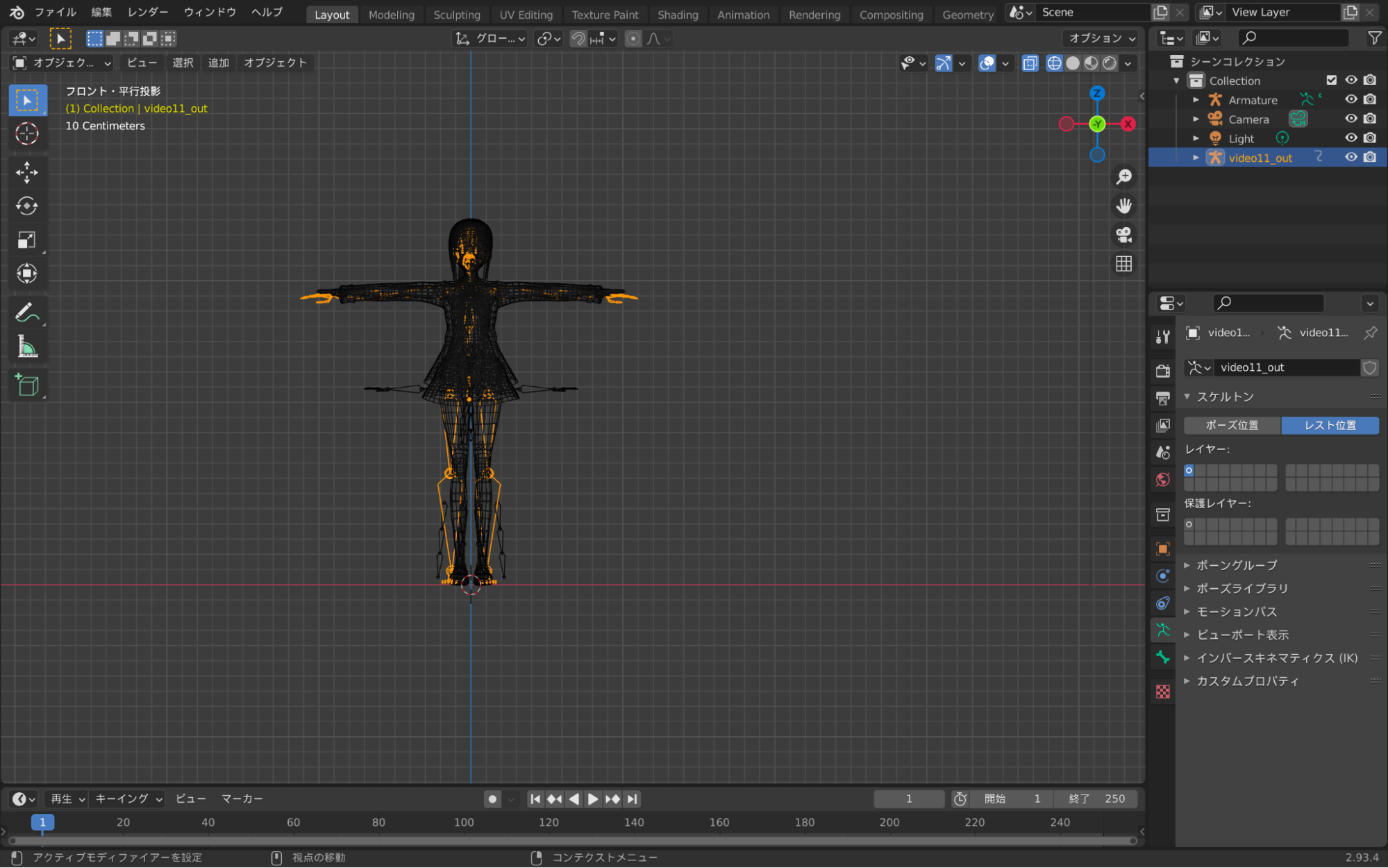
5. 重複頂点を解消する
このまま3Dモデルとボーンを結合すると結合時にエラーとなってしまいます。
そのため3Dモデルの重複頂点を解消します。
手順としてはこちらのサイト を参考に行いました。
6. 3Dモデルについているポーズ情報を削除する
このモデルにはあらかじめポーズ情報がついているため、そちらを削除します。
7. 3Dモデルとボーンのペアリングを行う
3Dモデル、ボーンを選択状態にし、アーマチュア変形(自動のウェイトで)を行います。
するとBlenderが自動で3Dモデルとボーンの紐付けを行ってくれます。本来は手動で微修正をした方がより良いものとなると思いますが、大変なので今回は自動のままで進めます。
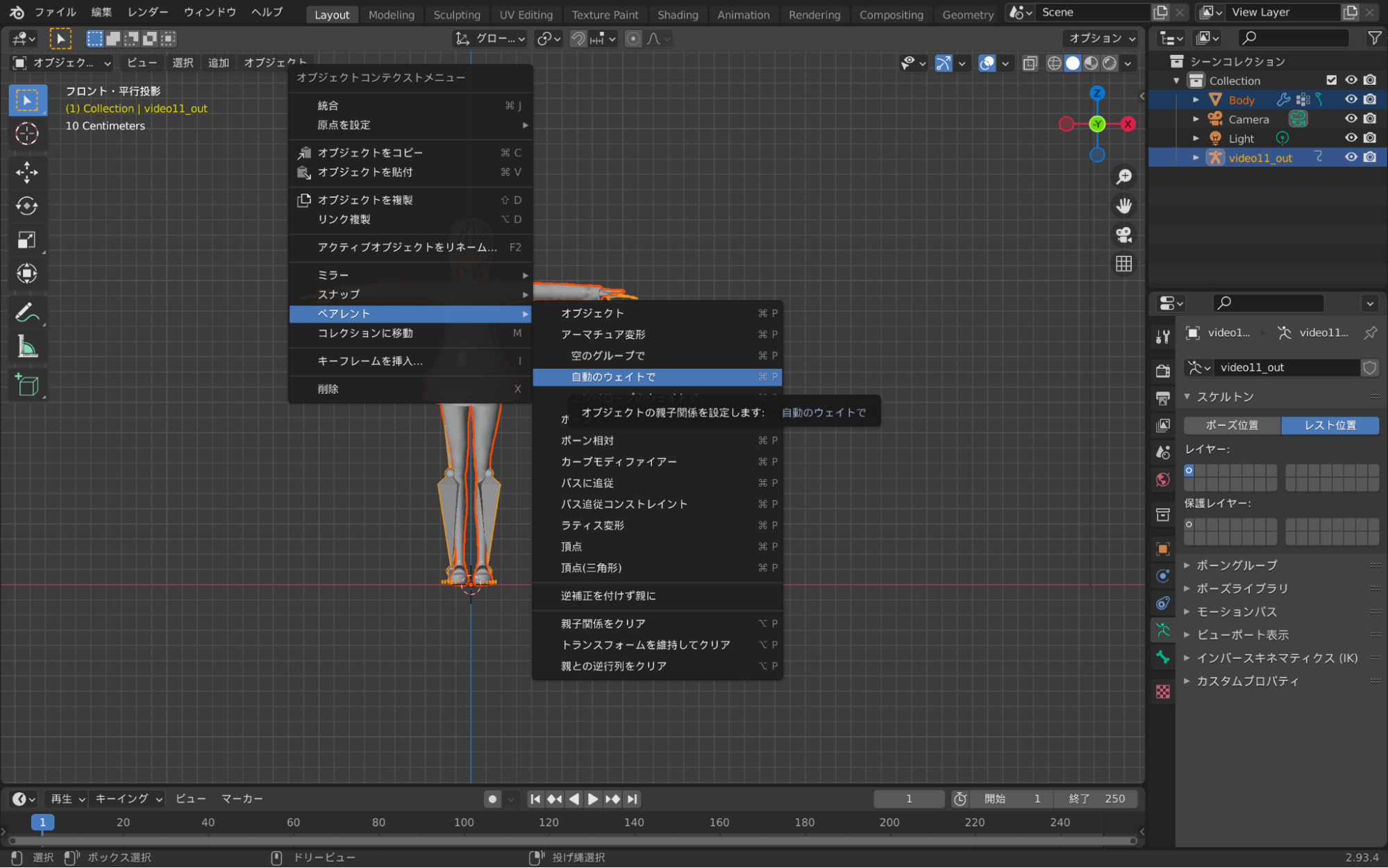
8. ボーンのレスト状態を解除して再生
先ほど設定したボーンのレスト状態を解除し、再生ボタンを押すことで3Dモデルがモーションデータにしたがって動き出します。
最終アウトプット動画
こちらがモーションデータ(bvh)と3Dモデルの紐付けを行なった最終アウトプットとなります。(fpsが低いのは自分の使っているPCの問題です)
動画①最終アウトプット
動画②最終アウトプット
カクついていたり、腕が体に食い込んだり、まだまだクオリティ向上の余地はありそうですが、まずまずのクオリティで生成ができています。
まとめ
今回ご紹介した動画以外でもMocapNETで独自の生成を行ってみましたが、やはり上手くいくものいかないものがあります。
個人的な感覚としてはMocapNETでは正面を向いている動画からは比較的綺麗にモーションが抽出できますが、回転したり横を向いているものは生成が難しい印象があります。
これはおそらくMocapNETのアルゴリズム内で向きの判定を行っている特性からくるものではないかと思っています。
それでもモーション作成のベースとして利用したり、ちょっと遊んでみる感覚で使ってみるものとしては十分なクオリティが出せているのではと思いますので、今後こういった技術を何かに活用していけたら良いなと思います。
このブログについて
KLabのゲーム開発・運用で培われた技術や挑戦とそのノウハウを発信します。
おすすめ
合わせて読みたい
このブログについて
KLabのゲーム開発・運用で培われた技術や挑戦とそのノウハウを発信します。