
GUI要素検出における画像処理とディープラーニングの組み合わせアプローチの論文紹介
はじめまして、機械学習グループのGANBAT NYAMKHUUです。私達は日々、スマートフォンをボタンやテキストボックスなどのGUI (Graphical User Interface)を通して操作しています。とくにゲームアプリでは、GUIの見た目はキャラクター画像だったり光るバナーだったりと多種多様です。機械学習グルー
プでは、これらのGUIを画面から検出してゲームを自動的にデバッグしてくれるGUIテストツールの研究開発を進めています。GUIテストツール開発ではObject Detection for Graphical User Interface: Old Fashioned or Deep Learning or a Combination?という論文を参考にしました。この記事ではその論文の内容を紹介します。
論文紹介に入る前に、ゲーム開発においてなぜGUIテストツールが重要なのかをご説明します。ゲームを誰もがストレスなく遊べるようにするためには、サクサク動作し、触っているだけで楽しいGUIが必要です。プレイしているうちに処理落ちしたりクラッシュしたりすることは避けなければなりません。とはいえ、スマホゲームは世界中の人々が様々な端末で遊ぶものですから、あらゆる条件下での動作テストを人手で行うことは現実的ではありません。テストコードを書いて自動化しようとしても、変化の速いゲーム開発ではテストコードをメンテナンスしきれなくなりがちです。ゲーム本体が変更されてもテストコードを変更せずにすむような自動テストツールがあれば嬉しいですね。そこで機械学習グループでは、ゲーム画面から操作できる要素(GUI要素)を検出してゲームを自動プレイしてくれるようなGUIテストツールを研究開発しています。そのようなGUIテストツールを開発序盤から導入することで、従来であれば
開発終盤に見つかりがちな下記のような不具合を早期に発見・修正し、世界中の誰もがスムーズに遊べるゲームを提供したいと考えています。
- UI/UXに関する問題
- CPU、メモリ、描画、I/O、通信、バッテリー、端末温度などの過負荷
- 全機能を結合したときに初めて生じる問題
- 実機でしか発生しない不具合
- 特定の機種・OSバージョンでのみ生じる問題
そこで、GUIテストツールのGUI要素検出機能の開発において以下の論文を参考にしました。
タイトル: Object Detection for Graphical User Interface: Old Fashioned or Deep Learning or a Combination?
論文リンク:
関連コード:
この記事で利用している全ての図および表は論文から引用したものになります。また、論文特有の用語は英表記でそのまま利用します。以下の内容を紹介いたします。
- 概要
- 問題スコープと既存手法
- 実験
- 提案手法
- まとめ
1. 概要
ユーザーはGUI(ボタン、テキスト、画像、ウィジェットなど)を介してアプリケーションを操作します。GUI要素(GUI element)の検出はGUIテストをはじめ、GUIコード生成、GUI検索など多くのタスクに役立ちます。GUIの検出は大きくインストゥルメンテーションベースの手法とピクセルベースの手法に分けられます。インストゥルメンテーションベースの手法はGUI要素を認識するAPIやインフラストラクチャを必要とします。一方、ピクセルベースの手法はGUIの画像から直接GUI要素を検出するためより一般的に用いられます。コンピュータビジョンにおける物体検出とは画像や動画から特定の物体(人間、建物、車
など)を検出することです。一般的に物体検出タスクは領域検出(bounding-boxの配置)とその領域の分類という2段階となります。既存の手法は画像処理ベースとディープラーニングベースの手法に分けられます。画像処理ベース手法のほとんどではbottom-up戦略が利用されます。Bottom-up戦略とはエッジや輪郭などのプリミティブな特徴を抽出し、それらを徐々に集約することで物体を検出します。一方、ディープラーニングベースの手法では大量の画像データから特徴抽出と集約ルールを学習します。
GUI検出は特殊な(domain-specific)物体検出タスクと言えます。よって、一般的な物体検出の手法をGUI要素検出に適用可能です。しかし、一般的な物体検出の代表的な手法をGUI要素検出に適用し、結果 をまとめている論文はありません。本研究はGUI要素検出タスクにおいて以下のように貢献します。
- まず、研究課題としてGUI要素の特性を把握し、一般的な物体検出との違いを明確にします。さらに、その違いがGUI要素検出のタスクをいかに困難とさせているかについて検証し、要件を定義します。
- 次に、既存の手法の性能比較が不十分であるため広範囲の性能比較実験を行います。GUI要素はNon-text要素とText要素に分けられ、異なる特徴を持ちます。そのためそれぞれに適した手法を適用する必要があります。Non-text要素の検出において画像処理ベースの手法とディープラーニングベースの手法を 適用します。Text要素の検出において既存のOCRツールとシーンテキスト検出用のディープラーニングベースの手法を適用します。性能比較実験から各手法の長所と短所を分析します。
- 最後に、性能比較実験の結果を踏まえ、GUI要素検出に適した新しい手法を提案します。さらに、提案手法を実装し、既存手法をベースラインとして性能を検証します。
2. 問題スコープと既存手法
GUI要素検出を行う際にしばしば見落とされがちなGUI要素固有の性質を特定します。また、GUI要素検出の代表的手法をまとめ、それらに対してGUI要素固有の性質がどんな困難さをもたらすかを指摘します。
2.1 問題スコープ
GUIと一般的な物体の特徴の違いは、大きく以下の4点になります。これらの特徴のために、GUI要素検出には高精度な領域検出が求められます。
クラス内の分散が大きい (Large in-class variance):
GUI要素の属性(高さ、幅、アスペクト比、テクスチャなど)は、表示するコンテンツおよびサポートするインタラクション、全体的なGUIデザインによって異なります。たとえば、Figure 1で示しているように、ButtonまたはEditTextの幅は、表示するテキストの長さによって変わります。また、ProgressBar
には様々なスタイル(垂直、水平、または円形)のものがあります。ImageViewは任意の画像オブジェクトまたはコンテンツを表示します。さらに、同じGUI機能であっても、デザイナーによってテキストや色、背景などが異なります。一方、人間、車、建物などの物理的物体は、1つのクラス内で共通する形状や
外観を持っています。このようにクラス内分散が大きいことは、GUI検出の主要な困難さとなります。
クラス間の類似性が高い (High cross-class similarity):
GUI要素は、異なるクラスのGUI要素と同じサイズおよび形状、視覚的特徴を持つ場合があります。たとえば Figure 1で示しているように、ButtonとSpinnerとChronometerはすべて長方形で、中央にテキストがあります。ButtonとSpinnerの違いは、Spinnerの右側にある小さな三角形にあります。EditTextとTextViewの場合は細い下線で区別されます。
一般的な物体検出タスクのCOCO2015データセットでは馬、トラック、人、鳥など、クラス間で異なる特徴を利用します。クラス間の類似性が高いことは、GUIの分類を困難にするだけでなく、GUIの領域検出と分類を同時に学習するディープラーニングモデルにとってGUI検出も困難にします。
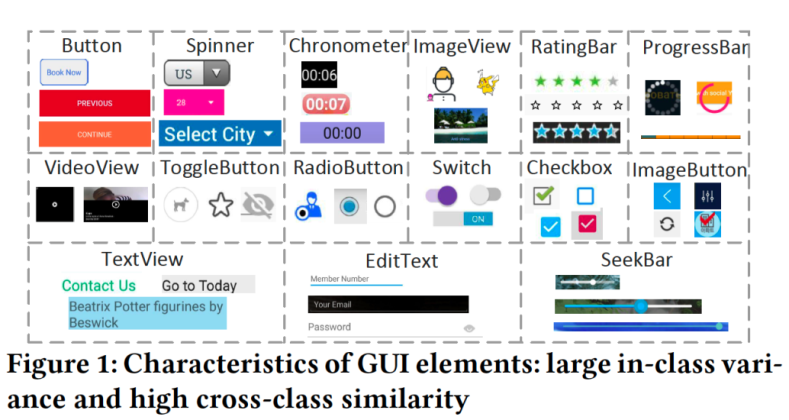
様々な要素の組み合わせ (Mix of heterogeneous objects):
GUIはウィジェットや画像、テキストなどを表示します。ウィジェットは、人工的に描画されたオブジェクトで、大きいクラス内分散と高いクラス間類似性をもちます。ImageViewは単純な長方形ですが、任意のコンテンツとオブジェクトを表示します。GUI要素検出タスクでは、ImageView自体を検出したいのですが、画像内のオブジェクトは検出したくありません。
また、Figure 6とFigure 4では、GUIテキストと一般的なドキュメントテキストの主な違いについて確認できます。つまり、GUIテキストは背景が非常に複雑で、他のGUI要素に近いことがよくあります。そのため、正確なテキスト検出が要求されます。これらの様々な要素の組み合わせにGUI要素の検出手法は対応する必要があります。
まとめられたシーンと近接した要素(Packed scene and close-by elements):
Figure 6に示しているように、GUI、特にモバイルアプリケーションのGUIでは多くのGUI要素がまとめられ、ほとんどの場合すべての画面スペースをカバーしています。この研究で利用しているデータセットでは、GUIの77%に7つ以上のGUI要素が含まれています。さらに、GUI要素は多くの場合、非常に接近し て配置され、それらは小さな隙間で区切られています。
一方、一般的な物体検出のCOCO(2015)データセットでは、平均して1枚の画像に7つの物体がまばらに存在します。よって、GUI画像はひとまとまりのシーンと見なせます。ひとまとまりのシーンから物体を検出するタスクでは、近くの要素の影響を受け、正確なbounding boxの推定が難しくなります。
高精度の領域検出 (High accuracy of region detection):
物体検出では、予測されたbounding-boxの正確さを図るためにIoU(Intersection over Union)という指標が用いられます。人間はほとんどの場合、物体の半分以上を見れば認識できることから一般的な物体検出ではIoUのしきい値はIoU>0.5程度に設定されます。
一方、GUI要素の検出では、IoUの閾値を高く設定する必要があります。推定されたbounding-boxが正確でない場合、GUIのコード生成やGUIテストが失敗するからです。
2.2 既存手法
Table 1ではNon-text要素の検出における既存手法についてまとめています。各手法の詳細について調べたい方は論文の文献から参照していただければと思います。

Non-text要素の検出のおける画像処理ベースの手法は大きくedge/contour集約に基づく手法とtemplate-matchingに基づく手法に分けられます。Canny edgeとcontour mapという特徴量は実世界の物体の詳細なテクスチャを抽出できますが、GUI要素の形状やその組み合わせ方とは直感的に対応していません。特に、GUI要素が実世界の物体の画像を含んでいる場合、検出が間違いやすくなります。Template-matchingに基づく手法では高品質のサンプル画像またはGUI要素の抽象的なプロトタイプが必要となるため、手間やコストがかかります。そのため、シンプルで標準的なGUI(buttonやcheckboxなどのアイコン)のみに適用され、GUIが複雑になりがちなモバイルアプリケーションのGUI要素検出への適用は困難です。
一方、ディープラーニングベースの手法は大量のデータからGUI要素の特徴量とその組み合わせ方を学習します。しかし、GUI固有の性質に直面したときディープラーニングモデルがどれくらい有効にGUI要素の特徴量とその組み合わせ方を学習できるのかは明らかになっていません。また、ディープラーニング ベースの手法では深層の特徴量マップを利用し、bounding-boxを推定します。その深層の特徴量マップの1つのピクセルは元画像の複数のピクセル(ブロック)に対応するため、GUI要素検出に求められるbounding-boxの正確さを満たせるかどうかについて検証する必要があります。さらに、Faster-RCNNやYOLOv2の ようなanchor-boxベースの手法ではanchor-boxの高さ、幅、アスペクト比といったパラメータ設定が必要です。よって、パラメータ設定による影響を分析する必要があります。最後に、ディープラーニングベースの手法の検出性能は学習データに大きく依存します。そのため、学習データの量による影響を分析する必要があります。
Text要素の検出において、既存手法ではOCRツールのTessaractを利用し、検出を行っています。Tessaractはドキュメントテキスト検出用に設計されたため、シーンテキストのような複雑な背景におけるGUIのText要素の検出に適しているかどうかについてはシーンテキスト検出用の手法と比較し、検証する必要があります。また、Text要素とNon-text要素を一つのモデルで検出した場合とそれぞれの専用モデルで検出した場合の性能比較が必要です。
3. 実験
3.1 リサーチ・クエスチョン
領域分類についてはすでに良く検証されたCNNベースの画像分類器があるため、本研究ではGUI要素検出における領域検出に関する3つのリサーチ・クエスチョンに焦点を当てます。
検出性能(Performance):
Non-text要素の検出において各手法の検出性能を比較します。
感度(Sensitivity):
ディープラーニングベースの手法においてanchor-boxのパラメータ設定と学習データの量による精度分析を行います。
Text要素の検出(Text detection):
Text要素をシーンテキストとして検出し、ドキュメントテキストとして扱った検出結果と比較します。また、Non-text要素とText要素をそれぞれの専用モデルで検出した場合と一つのモデルで検出した場合の性能を比較します。
3.2 実験設定
データセットについて説明します。
Ricoデータセットを利用して、実験データセットを作成します。GUI要素の種類としてFigure 1で示しているAndroidプラットフォームで一般的に使用される15種類を対象とします。Ricoデータセットには66,261個のGUIが含まれており、その内15,737個のGUIを除外しました。除外されたGUI要素は以下となりま す。
- 5,327個はAndroidのホーム画面やSNSのログインページやブラウザへのリダイレクトなどアプリの外部で取得されたGUIとなります。
- 2,066個はレイアウトの説明や無効な境界を持つ要素など検出ができない要素となります。
- 709個は15種類のGUI要素のいずれも含んでいません。
- 7,635個はText要素またはNon-text要素のみ含まれているため除外しました。
よって、残りの50,524個のGUI画像を実験で用います。結果として実験のデータセットは27カテゴリーの8,018個のアプリから取得されたものとなります。全てのGUI要素数は923,404個でその内Non-text要素は426,404個、Text要素は497,000個となります。このデータセットを8:1:1(40K:5K:5K)の割合でtrain、 validation、 test用(一つのアプリの全てのGUIをいずれかに含まれる)に用います。 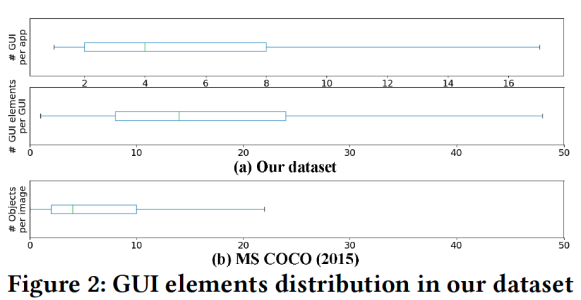
既存の手法をベースラインとして簡単に説明します。
REMAUI
この手法ではText要素とNon-text要素を別々に検出します。Text要素検出にはTesseract、Non-text検出には画像処理ベースの手法が用いられます。画像処理ベースの手法はGaussianフィルタでノイズを除去し、Canny edgeを検出します。次に、検出されたedgeをマージし、contourを抽出し、部分的にオーバーラップする領域をマージすることでGUI要素のbounding-boxを検出します。
Xianyu
Xianyuは、Alibabaが開発しているGUI画像からコードを生成するツールです。この研究ではGUI要素検出の部分のみ利用します。Xianyuは、画像を2値化し、画像全体を水平と垂直に半分に再帰的にカットして、GUI要素を取得するアルゴリズムとなります。2値化画像にLaplaceフィルタを適用し、急激な強度変 化の領域を抽出することでedgeとcontourを抽出します。その後、flood-fillアルゴリズムを適用し、繋がっている領域(connected regions)を特定します。
Faster-RCNN
Faster-RCNNは、物体検出のための2段階のanchor-boxベースのディープラーニングベースの手法です。最初に、Region proposal network(RPN)によって関心領域 (region of interests, RoIs)と呼ばれる物体が存在している可能性が高い領域の集合を抽出します。具体的には、RPNはanchor-box(事前に定義されたスケールとアスペクト比を持つ)を利用し、特徴量マップから物体が存在する領域を特定します。2段階目として各関心領域に対してCNNベースの分類器を適用し、物体を認識します。
YOLOv3
YOLOv3は、1段階のanchor-boxベースの物体検出手法です。YOLOv3ではFaster-RCNNと異なり、anchor-boxのパラメータであるスケールとアスペクト比を設定する必要はありません。Anchor-boxのパラメータは学習データに対してk-means法を適用し、クラスタリングを行い、各クラスタの中心(平均)の値を利用 します。YOLOv3はCNNによって特徴量を抽出します。その特徴量の各グリッドに対してbounding-boxの集合を出力します。各bounding-boxに対して物体らしさ(objectness score)の算出とbounding-boxの回帰とクラスの分類を同時に行うことで物体を認識します。
CenterNet
CenterNetは、anchor-free(anchor-boxなし)の1段階の物体検出手法です。この手法は物体の左上隅と右下隅の位置と中心を予測し、それらを組み立てることでbounding-boxを推定します。左上隅と右下隅の距離がしきい値より小さく、bounding-boxの中心点の認証スコア(certerness score)がしきい値より高 い場合には物体として検出します。
Tesseract
Tesseractは、ドキュメントテキスト用のOCRツールです。これは、テキスト行の検出とテキスト認識の2つのステップで構成されています。この研究ではテキスト行の検出のみ利用します。テキスト行の検出は画像処理に基づきます。最初に画像をバイナリマップに変換し、次に連結成分を分析し、要素の輪郭を 抽出します。次に、これらの輪郭はブロブにグループ化され、さらにマージされることでテキスト行を検出します。
EAST
EASTは、シーンテキスト検出用のディープラーニングベースの手法です。まず、Feature Pyramid Network (FPN)によって特徴量を抽出します。次に、最終的な特徴量マップの各点に対して物体らしさ(objectness score)、上/左/下/右のオフセット、回転角を出力します。この研究では学習済みモデルを利用します。
モデルの学習について説明します。Faster-RCNN、YOLOv3、CenterNetのモデルの学習ではてCOCOデータセットで学習した学習済みモデルを初期重みとし、GUIデータセットでファインチューニングを行います。各モデルのバックボーンはFaster-RCNN、YOLOv3、CenterNetではそれぞれResNet-101、Darknet-53、Hourglass-52を利用します。学習パラメータとしてiteration数は160、バッチサイズは8、optimizerはAdamに設定しました。
XianyuとREMAUIではパラメータチューニングを行い、最適な設定で評価を行います。
全ての実験ではbounding-boxが重複した場合にnon-maximum suppression (NMS)を適用し、IoUに設定したしきい値より高い予測結果の中から物体らしさ(objectness score)が一番高い結果を出力します。物体らしさのしきい値を設定するためにvalidationデータセットを利用します。モデルの評価ではprecision、recall、F1-scoreの指標を利用します。ほとんどの実験でIoUしきい値を0.9に設定します。
検出性能(Performance)
まず、Non-text要素の検出性能を5つの手法を用いて検証します。Anchor-boxの設定はFaster-RCNNではcustomized anchor-box (詳細について次の感度実験で説明します)とYOLOv3ではk=9を利用します。
まず、IoUによる検出性能を見てみます。Figure 3では、IoUのしきい値を0.5から0.9まで変化させた時の5つの手法の性能(Precision、Recall、F1-score)を示しています。すべてのディープラーニングベースの手法ではIoUのしきい値が高くなるとF1-scoreは、Faster-RCNN、YOLOv3、およびCenterNetではそれ ぞれ31%、45%、および28%と大幅に減少します。一方、REMAUIとXianyuの画像処理ベースの手法ではF1-scoreは大幅に低下しませんが、ディープラーニングの手法のF1-scoreよりもはるかに低い結果となります。
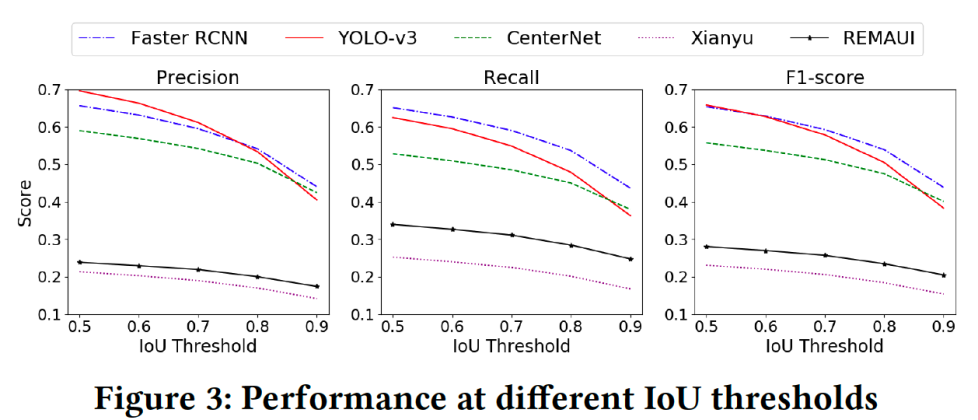
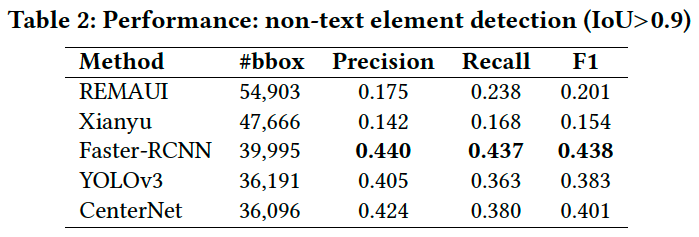
次に、GUI要素検出では高性能のbounding-box検出が要求されるためIoUのしきい値をIoU>0.9に設定し、各手法の性能を比較します。Table 2では各手法の検出性能を示しています。
Xianyuは一番低い結果となりました。Xianyuは背景が単純な場合のGUI要素検出性能は良いですが(Figure 6のcとd)、背景が複雑な場合はスライスとノイズ除去アルゴリズムが失敗します(Figure 6のaとb)。REMAUIはXianyuより性能は良いですが、ディープラーニングベースの手法に比べると低いです。Xianyu と同じように、複雑な背景と画像においてはノイズ除去とオーバーセグメンテーションが失敗します(Figure 6)。
ディープラーニングベースの手法の検出性能は画像処理ベースより良い結果になります。モデルは大量のデータで学習しているため、背景に画像を持つ場合でもGUI要素がうまく検出できる場合もあります。しかし、bounding-boxは統計的な回帰モデルによって推定されるためあまり正確ではありません。GUIの一つの特徴であるクラス間の類似性のために、2段階のFaster-RCNNの検出性能は1段階のYOLOv3とCenterNetの性能より良い結果となります。その原因は2段階のモデルは1段階のモデルに比べてGUI要素の検出と分類はパイプラインとなるため相互干渉が少ないからです。Figure 3からわかる通り、低いIoUの場合YOLOv3の性能はCenterNetより良いです。ディープラーニングベースの手法ではIoUのしきい値と検出精度のバランスをとることは困難です。
感度(Sensitivity)
ここで、Anchor-boxベースの手法においてanchor-boxのパラメータ設定と学習データの量に対する検出性能を分析します。まず、Table 3ではパラメータ設定による性能比較結果を示しています。パラメータ設定としてDefault、Customized、Union、Intersectionの4種類があり、それぞれについて以下に説明します。
Faster-RCNNでは
- Default設定:3つスケール(128、256、512)および3つのスペクト比(1:1、1:2、2:1)
- Customized設定:5つのスケール(32、64、128、256、512)および4つのアスペクト比(1:1、2:1、4:1、8:1)
Customized設定はデータセット内のGUI要素に頻出するスケールとアスペクト比から決定されます。GUI要素のサイズを考慮して、2つの小さなスケール32と64を追加します。さらに、GUI要素の大きな変動に対応するために、さらに2つのアスペクト比を追加します。
YOLOv3ではクラスタ数を文献で一般的に使用されている値に設定します。
- Default: K=5
- Customized K=9
データセット内のGUI画像からk-means法を用いてanchor-boxのパラメータを自動的に算出します。
Table 3ではIoU>0.9の時のanchor-boxのパラメータ設定による検出性能結果を示しています。
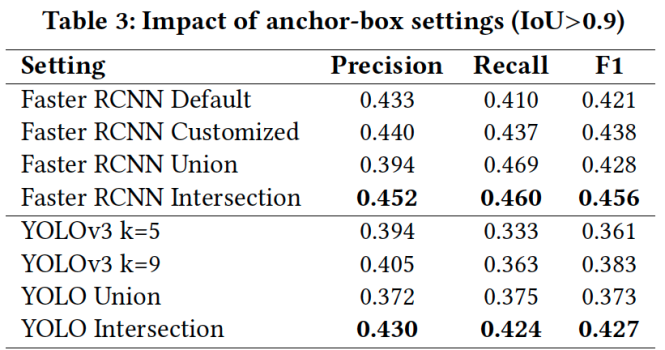
Anchor-boxのスケールとアスペクト比を多数使用してもF1-scoreはわずかにしか増加しないことは驚きです。
DefaultとCustomized設定のTP(True Positive)を見てみるとFaster-RCNNでは55%、YOLOv3では67%オーバーラップしています。GUI要素のスケールとアスペクト比は標準的な分布に従うため、少数のanchor-boxを使用しても、要素分布の大部分をカバーできます。異なる設定がいくつかの異なるbounding-boxを検出するので、互いに補完し合う可能性があるかどうかを確認します。そのために、検出されたボックスを2つの設定でマージする2つの戦略を採用します。Union戦略とIntersection戦略です。Union戦略とIntersection戦略では2つのbounding-boxがオーバーラップした場合、それぞれの領域のunionとintersectionを取得することで2つのbounding-boxをマージします。Union戦略はF1-scoreに大きな影響を与えません。つまり、bounding-boxが大きくなることはあまり役に立ちません。一方、Intersection戦略ではFaster-RCNNとYOLOv3の両方においてF1-scoreが向上しました。boundind-boxの共通部分は2つの設定で確かめられた領域なので、より確かであるというのは妥当に思えます。
次に学習データ量に対する性能比較実験の結果について説明します。この実験においてanchor-boxのパラメータは、Faster RCNNではCustomized、YOLOv3ではk = 9を使用します。学習データの量として2K、10K、40KのGUI画像データを使用してモデルを学習し、性能比較実験と同じテストデータセット(5K)で評 価します。2Kと10Kの画像データは40Kの画像データからランダムに選択されています。Table 4に結果を示しています。学習データが減少すると、すべてのモデルの性能が低下します。ディープラーニングモデルは、十分な学習データがないと、GUI要素の特徴を効果的に学習できません。
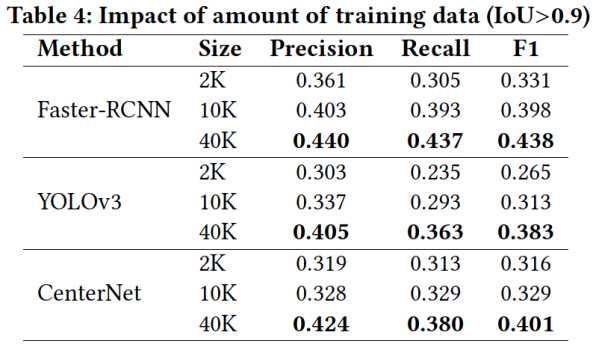
3つのモデルの検出性能を比較すると、3つの学習においてYOLOv3の結果は一番低いです。これは、1段階のanchor-boxベースのモデルの学習が難しいことを示しています。Faster-RCNNは少量の学習データ(2Kまたは10K)でYOLOv3およびCenterNetの大量の学習データ(10Kと40K)の検出性能に比べて同等のF1-scoreを示しています。よって、2段階のモデルは1段階モデルよりGUI要素の検出に適していることになります。また、1段階のモデルではanchor-freeのCenterNetの性能はYOLOv3の性能より良い結果になりました。
Text要素とNon-text要素を一つのモデルで検出するか個別のモデルで検出するか
既存手法ではText要素とNon-text要素は視覚的特徴が大きく異なるためそれぞれの専用のモデルで検出しています。しかし、これが必須なのかを確かめるために、Text要素とNon-text要素を単一のモデルで検出する実験を行います。実験ではFaster-RCNN、YOLOv3、およびCenterNetを学習します。Anchor-box設定はFaster-RCNNではCustomized、YOLOv3ではk = 9を使用します。モデルは40KのGUI画像で学習し、5Kの画像でテストします。
結果をTable 5に示します。 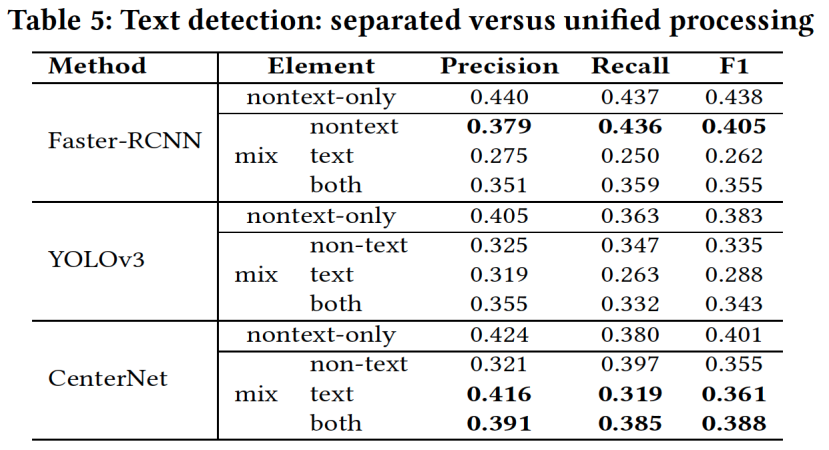
Faster-RCNNはText要素とNon-text要素を一緒に学習した場合でもNon-text要素の検出性能が一番良い結果となりました。全ての手法において、Non-text要素の検出性能を見てみると、Text要素とNon-text要素を一緒に学習した場合はNon-text要素のみで学習した場合より性能が低くなりました。よって、Text要素を一緒に学習することでNon-text要素の学習が妨げられることがわかります。
CenterNetは、Text要素の検出および全体の検出性能においてFaster-RCNNとYOLOv3より良い結果を示しています。また、Text要素とNon-text要素で同等な検出性能になりました。その原因としてCenterNetはanchor-freeベースの手法であるため様々なテキストパターンに柔軟に対応していることが考えられます。しかし、Text要素の検出におけるCenterNetの検出性能は不十分です。Text要素は常に単語と行の間にスペースがあります。これらのスペースが存在するため、CenterNetは、オブジェクトのコーナーを組み立てるときに、部分的なText要素を検出したり、別々のText要素を誤って1つの要素としてグループ化し たりすることがよくあります。
ドキュメントテキストかシーンテキストか(OCR vs Scene text detection)
次に、シーンテキストとして検出した場合の検出性能を比較します。単一のモデルでText要素およびNon-text要素を検出することは不可能であるため、GUIテキストの検出に最も適切な方法を調査します。既存の手法(REMAUI、Xianyuなど)では、TesseractなどのOCRツールを使用しています。一方でGUIテキストは、ドキュメントテキストよりもシーンテキストに似ていることが観察されています。そのため、GUIテキスト検出にシーンテキスト検出用のディープラーニングベースのEASTを適用し、Tesseractと検出性能を比較します。GUIテキストでファインチューニングをせずに、学習済みのEASTモデルを直接利用しま す。
Table 6に結果を示します。結果として、EASTの検出性能はTesseractよりも大幅に高くなっています。
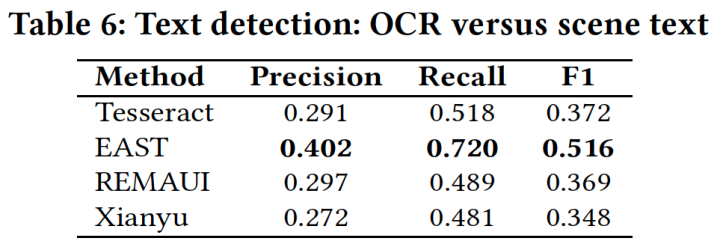
XianyuとREMAUIはどちらも、誤検知を除外するために、TesseractのOCR結果に後処理を適用します。ただし、GUIテキストの検出性能は大きく変わりません。EASTは、GUIウィジェット(Figure 4(c)のボタンラベルなど)のテキストをはじめほぼ全てのGUIテキストを検出します。ただし、GUIウィジェット上のこれらのテキストは、単独のテキストではなく、ウィジェットの一部と見なされます。これにより、検出されたテキストが正確であっても、ground truthデータに対するEASTのprecisionに影響します。Figure 4に、いくつかの検出結果を示します。
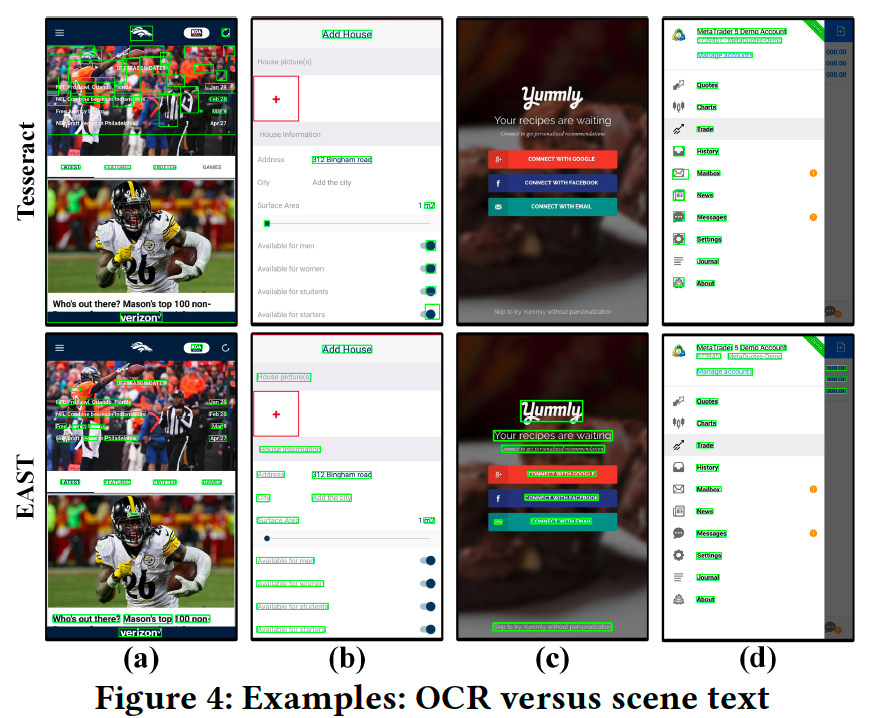
Tesseractは、Figure 4(d)の左側でのみ、EASTと同等の結果を達成します。ここでは、テキストがドキュメントのように白い背景に表示されています。他の検出結果からは、GUIテキストをシーンテキストとして扱う利点を確認できます。一つ目に、EASTは画像背景の場合に正確な検出ができますが(Figure 4(a))、Tesseractはそのような画像の背景の場合に多くの誤検出を出力します。二つ目に、EASTはコントラストの低い背景におけるテキストを検出できますが(Figure 4(b))、Tesseractはそのようなテキストを見逃すことがよくあります。三つ目に、EASTはNon-text要素(たとえば、Figure 4(b)の右下のス イッチボタンやFigure 4(d)の左側のアイコン)を無視できますが、TesseractはNon-text要素を誤って検出することがよくあります。
4. 提案手法
上記の実験結果を踏まえて、GUI要素検出に適した新しい手法を提案します。提案手法はGUI要素の領域検出では画像処理ベースの手法を利用し、GUI要素の認識(クラス分類)ではデプロイが簡単なディープラーニングベースの手法を利用します。
4.1アプローチ設計
GUIの検出は、Non-text要素とText要素をそれぞれの専用のモデルで検出します。Text要素の検出では学習済みのEASTを使用します。Non-text要素において領域検出と領域分類の2段階となります。領域検出はtop-down coarse-to-fine戦略を適用した画像処理ベースの手法となります。この戦略は既存の画像処理ベースのedge/contourのプリミティブな特徴量を抽出し、それらを集約するアルゴリズムと逆のアプローチです。
4.1.1 Non-text要素の検出
性能比較と感度の実験結果から、一般的なディープラーニングベースのモデルは使用したくありません。まず、安定したパフォーマンスを実現するために大量の学習データが必要となります。さらに、モデルの性能は、学習データセットが十分であっても、モデルの構造によって異なります。また、ディー プラーニングベースの手法ではbounding-boxの予測結果はあまり正確ではありません。GUI要素の検出ではbounding-boxがかなり正確であることが求められます。残念ながら、anchor-boxベースのモデルもanchor-freeモデルもこの要件を満たしていません。
一方、画像処理ベースの手法では性能は高くないですが、ディープラーニングモデルとは異なり、学習データの作成およびモデルの学習を必要としません。さらに、画像処理ベースの手法でGUI要素を検出した場合bounding-boxはかなり正確であり、これは望ましいことです。よって、Non-text要素の検出には 既存の画像処理ベースを改良した手法を適用します。ただし、既存の手法では、物体の詳細の特徴(エッジや輪郭など)を集約するbottom-up戦略が使用されています。このbottom-up戦略は、特に複雑な背景や画像の場合には検出性能が低下します。Figure 5に提案手法の流れを示します。提案手法はbottom-up 戦略と完全に異なるtop-down coarse-to-fine戦略を適用します。 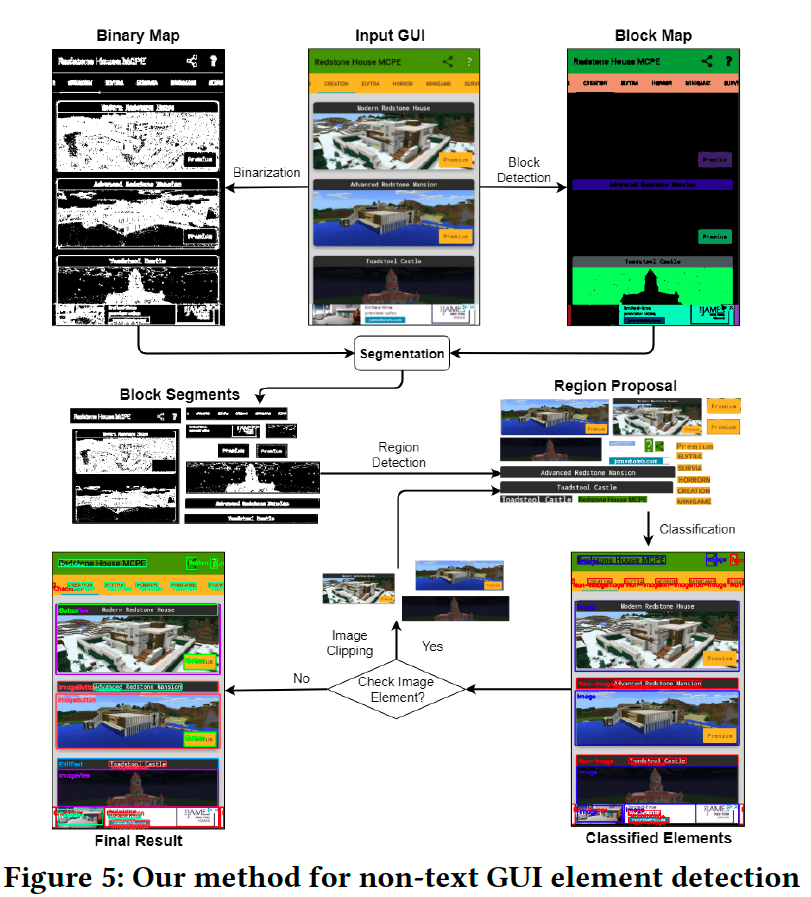
この提案手法では、GUIのレイアウトとGUI要素の形状および境界の規則性、また、人工GUI要素と物理的物体の形状と境界の大きな違いに焦点を当てています。
提案手法の詳細について説明します。まず、GUIのレイアウトブロックを検出します。直感的には、GUIはGUI要素を含むブロックで構成し、これらのブロックはほとんどの場合は長方形の形状をしています。最初に入力GUIのbinary map上でflood-fillingアルゴリズムを適用し、同様の色の領域を検出し、次に 形状認識によって領域が長方形であるかどうかを判断します。各長方形領域はブロックとなります。最後に、Suzuki's Contour tracingアルゴリズムを適用し、ブロックの境界を抽出し、block mapを生成します。Figure 5では、表示を見やすくするために、検出されたブロックを異なる色で示しています。ブロ ックには通常、いくつかのGUI要素が含まれていますが、一部のブロックは特定のGUI要素に対応している場合があります。
次に、GUIのbinary mapを生成し、検出されたブロックごとに、binary mapの対応する領域をセグメント化します。二値化により、入力画像が白黒画像に簡略化され、前景のGUI要素を背景から分離できます。
既存の方法は、Canny edge検出とSobel edge検出を介して二値化を実行します。これらは、シーン画像の細かいテクスチャの特徴を保持するように設計されているためGUI要素検出には適切ではありません。たとえば、Figure 6のImageViewの場合、画像内の物体ではなく、ImageView要素自体を検出する必要 があります。GUI画像のgradient mapに基づいて、シンプルで効果的な二値化手法を提案します。Gradient mapは、隣接するピクセル間の勾配の大きさの変化を取得します。ピクセルの勾配が隣接するピクセルと小さい場合は、binary map上で黒になり、それ以外の場合は白になります。Figure 5に示すように、GUI要素は、binary mapの背景から、黒い背景での白い領域または白いエッジの黒い領域として目立ちます。次に、Connected component labelingを適用して、各binary block segmentのGUI要素領域を識別します。GUI要素は任意の形状でありますが、検出された領域をカバーする最小の長方形の領域をbounding-boxとして識別します。提案の2値化方法では、non-GUIオブジェクトの詳細の特徴はあまり保持されませんが、non-GUIオブジェクトの形状(写真内の建物など)は、binary mapに引き続き存在する可能性があります。これらのノイズの多い形状は、GUI要素検出のための既存のbottom-up集約方法に干渉し、GUI要素の過剰なセグメンテーションをもたらします。対照的に、top-down検出戦略では、緩和されたグレースケールマップを使用して大きなブロックを検出し、厳密なbinary mapを使用してGUI要素を検出するため、これらのnon-GUIオブジェクトの影響を最小限に抑えます。ブロックが画像として分類されている場合、このブロック内のGUI要素をそれ以上検出しません。 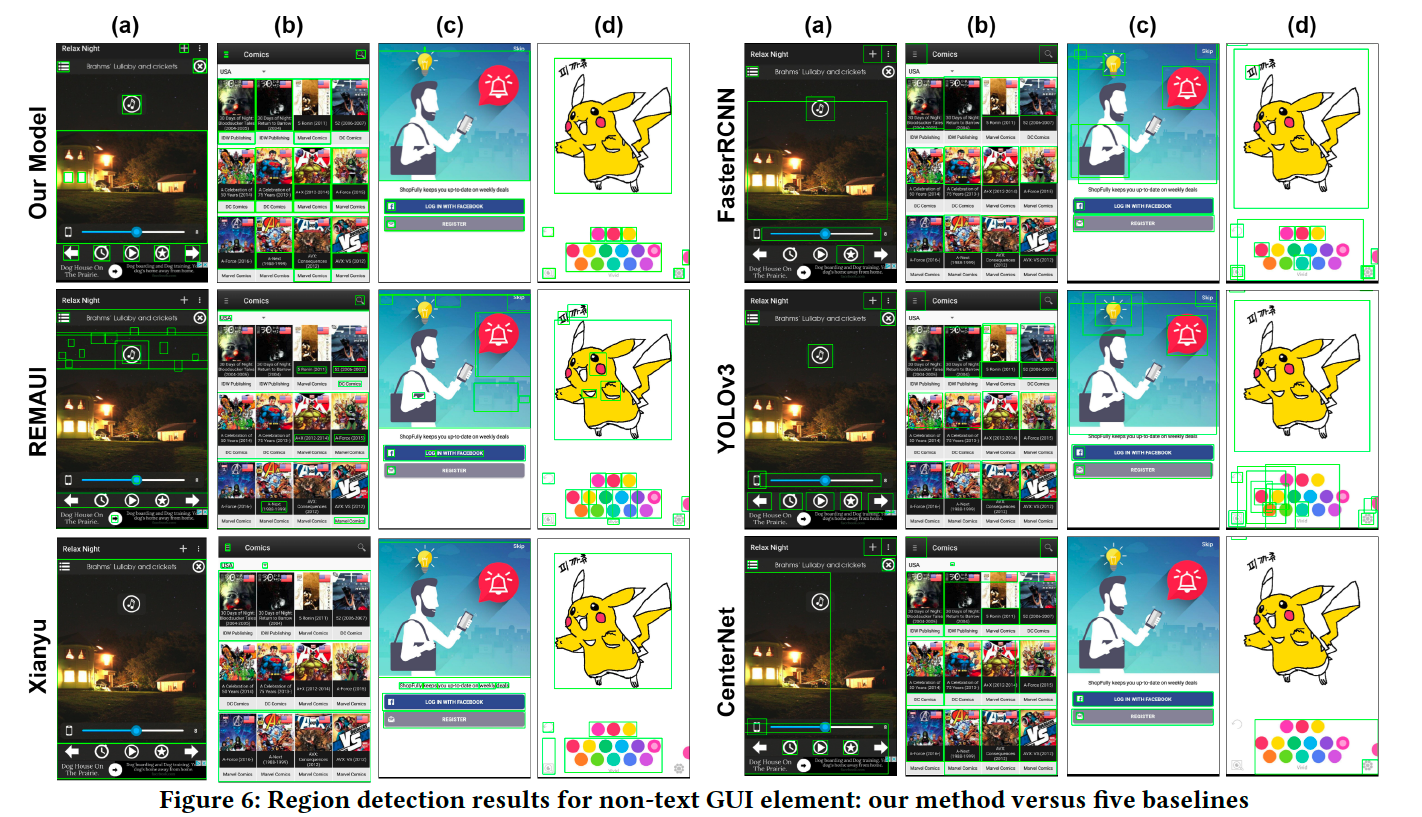
Non-text要素の分類
入力GUIで検出されたGUI要素領域ごとに、ResNet50モデルによってクラス分類を行います。GUI要素のクラスとしてFigure 1に示すように15種類となります。Resnet50モデルはImageNetデータで学習し、さらに、GUIのデータセットの学習用の40K画像からランダムに選択された90,000GUI要素(要素種類ごとに6,000)のデータでファインチューニングを行います。
Text要素の検出
GUIテキストをシーンテキストとして扱い、Non-text要素とは別に検出する必要があることを実験で示しました。そのため、提案手法ではディープラーニングベースのシーンテキスト検出用のEASTを使用してGUIテキストを検出します。Figure 4(c)に示すように、EASTは、非画像GUIウィジェットの一部であるテキスト(ボタンのテキストなど)を検出する場合があります。したがって、検出されたGUIテキストが非画像GUIウィジェットの領域内にある場合、このテキストを除外します。
提案手法の評価
性能比較実験のテストデータを用いて提案手法とベースラインの性能を比較します。
Table 7では、Non-text要素、Text要素また、both(両方の要素)の領域検出の性能を示しています。 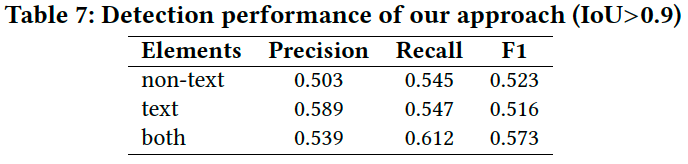
Non-text要素の場合、提案手法のF1-scoreは、最良のベースラインであるFaster-RCNNの0.438に対し0.523となります。Text要素の場合、全体的にEASTの結果と同じですが、GUIウィジェットの一部である検出されたテキストの一部を破棄するため、精度はEASTより高いです。しかし、これはrecallを低下さ せます。全ての要素の場合、最良のベースラインCenterNetよりも精度が高いです(F1の0.388に対して0.573)。Figure 6では、提案手法と5つのベースラインによる検出の例を示しています。
REMAUIやXianyuと比較すると、より多くのGUI要素を検出し、Non-text要素においてノイズの少ない正確な領域を検出します。また、3つのディープラーニングモデルよりも多くのGUI要素を検出します。ディープラーニングモデルでは画像内の物体をGUI要素として検出することに対して、提案手法ではブロックを検出するため画像内の物体を検出することは少ないです。
提案手法は全てのケースにおいて優れた検出をしているわけではありません。提案手法の誤検出する理由として大きく3つ挙げられます。一つ目に、同じ視覚的特徴(テキストラベルと境界線のないテキストボタン)を持つUI領域は様々なウィジェットに対応する場合があります。二つ目に、Figure 6(b)のような密なUIの反復領域では、検出結果に一貫性がないことがあります。三つ目に、テキストの領域がテキストラベルなのか、テキストを含むウィジェットの一部なのかを判断するのが難しい場合があります。たとえば、Figure 6(b)の上部にあるUSAを示すスピナーです。これらの誤検出の解決は今後の課題とします。
Table 8では、ベースラインの3つのディープラーニングモデルと提案手法の検出領域をCNNで分類した結果を示しています。
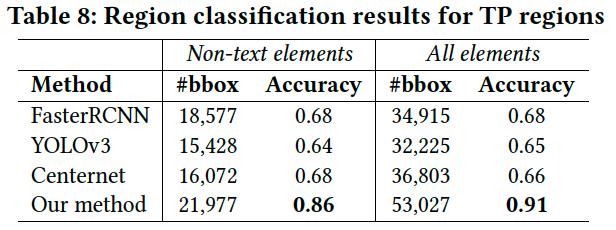
結果は、正確な領域検出(true-positiveのbounding-box)ができた場合の分類結果になります。Text要素はEASTによって直接検出されるため、Non-text要素とすべての要素の検出結果を示します。表からわかる通り、提案手法はより多くのtrue-positiveの検出と一番高い分類精度となります。
Table 9は、全体的な検出結果を示しています。つまり、検出されたすべての領域における分類が正しい予測結果となります。
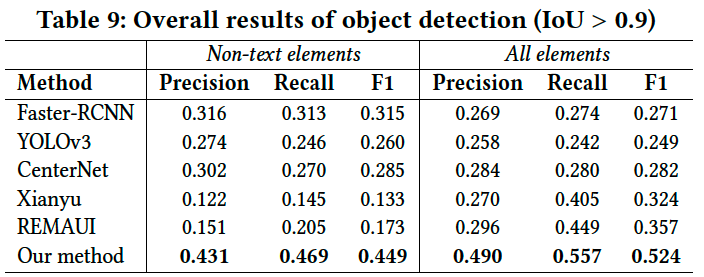
提案手法はベースラインに対してはるかに高い性能を示しています。
5. まとめ
GUI要素の検出と一般的な物体検出との4つの違い(大きなクラス内分散、高いクラス間類似性、まとめられたシーンと近接した要素、様々な要素の組み合わせ)についてGUIの特徴を踏まえて説明しました。これらの違いによって、GUI要素検出は既存の古典的手法でもディープラーニングベースの手法でも 困難なタスクとなっています。実験により、既存の画像処理ベースとディープラーニングベースの物体検出手法ではGUI要素の検出性能が不十分であることを確認し、その原因を解明し、効果的なGUI要素検出手法の設計方法を明らかにしました。これをふまえて新しい手法を提案しました。性能比較実験から提案手法は既存手法より優れた結果を示しました。
このブログについて
KLabのゲーム開発・運用で培われた技術や挑戦とそのノウハウを発信します。
おすすめ
合わせて読みたい
このブログについて
KLabのゲーム開発・運用で培われた技術や挑戦とそのノウハウを発信します。