
機械学習を用いたリズムアクションゲームの譜面制作
今回の記事ではKLab株式会社 (以下「KLab」)の機械学習を用いた取り組みの一つであるリズムアクションゲームの譜面制作の概要を理解していただくために関連技術を紹介します。KLab社員が書いたものではありませんが、参考にさせていただいている「Dance Dance Convolution」の論文を紹介いたします。
KLabではリズムアクションゲームにおける譜面制作支援システムの研究開発が進んでおり、譜面生成に用いる機械学習アルゴリズムをさらに高度化する目的で九州大学と共同研究を開始いたしました。共同研究の背景と研究概要はこちらの記事をご覧ください。
今回紹介する論文は譜面生成における機械学習の利用法が述べられている重要な論文なります。また、KLabの譜面制作支援システムの目的および解決しようとする研究課題はこの論文の内容とかなり一致します。紹介の内容は研究課題および解決アプローチに焦点を当てるため、実験結果や考察などは軽いレベルで説明させていただきます。詳細について知りたい方には論文を見ていただきたいです。
さっそくですが、論文紹介に入ります。この記事で利用している全ての図および表は論文から引用したものになります。以下の内容を紹介いたします。
- 概要
- データ
- 提案手法
- 実験
- まとめ
概要
Dance Dance Revolution (DDR)はリズムベースのビデオゲームであり、プレイヤーは楽曲に合わせて画面上に流れてくる矢印のシーケンスに従って、ダンスプラットフォームの矢印パネルをタイミングを合わせ足で踏んで踊って遊びます。プレイヤーのスコアは踏んだ矢印パネルが正しく、踏んだタイミングが正確になるほど高くなります。ステップチャートは難易度によって、ステップ数およびシーケンスの難しさが変わってきます。矢印パネルはup、down、left、rightの4種類になり、各パネルは on、off、hold、releaseの4つの状態のいずれかになります。DDRのコミュニティでは、オープンソースのStepManiaなどのシミュレーターを使用し、プレイヤーが独自のステップチャートを作成して遊べるようにしています。通常、著者がチャートのパックを作成し、プレイヤーが遊べるように配布しています。一般的に、パックは曲ごとに5つの難易度とそれぞれチャートを1つずつ含んでいます。
しかし、プレイヤーに不満が生じる問題があります。代表的なものとして以下の3つが挙げられます。
- ライセンスなどでパックの曲数が限定され、プレイヤーは自分の好きな曲で遊べないこと。
- 好きな曲のチャートが存在しても、繰り返して遊ぶことで飽きてしまうこと。
- プレイヤー自身が曲のチャートを作成するには高度な専門知識が必要となること。
よって、本研究の目的はチャート作成を自動化し、プレイヤーが好きな曲のチャートで踊れるようにすることです。具体的には、既存の曲の音声データに対して人間が作成したステップチャートを学習することで、新たな音声データに対してステップチャートを生成する機械学習モデルを構築します。このタスクを2つのサブタスクに分けてアプローチします。まず、ステップ配置(step placement)のタスクではステップを配置するタイムスタンプのセットを作成します。そのために、プレイヤーは曲の音声特徴量のほか、ゲームの難易度を調整する必要があります。次に、ステップ選択(step selection)タスクでは各タイムスタンプに配置するステップを選択します。このプロセスを図1に示します。
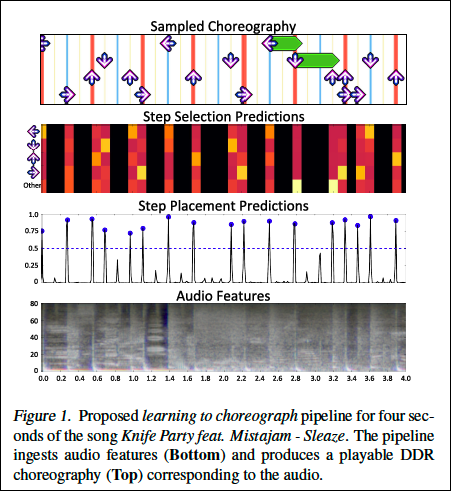
図1. 提案したステップ作成のパイプライン(曲 - Knife Party feat. Mistajam -Sleaze.)
入力となる音声の特徴量 (下)
作成したステップチャート (上)
データ
このアプローチでは大量のアノテーション付きデータセットが必要となるため、論文では2つの大きなデータセットを作成し(表1)、公開されています。
表 1. データセット
一つ目のデータセットFraxtilには90曲が含まれ、各曲は難易度(5種類)ごとにチャートがあります。一曲の難易度が異なるチャートは大幅に重複する傾向にあるが、難易度の低いチャートは難易度の高いチャートの厳密なサブセットではないことが分かります(図 3)。
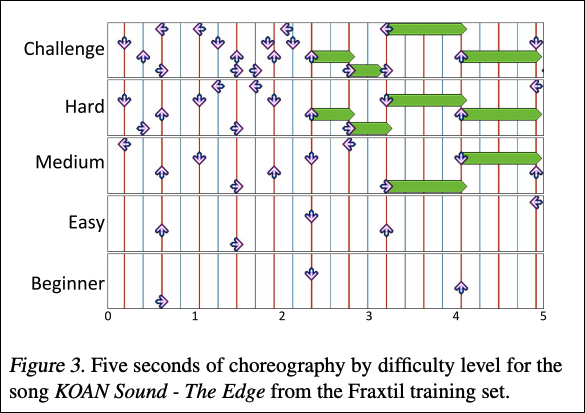
図 3. 5秒の曲における難易度ごとのステップチャート
(曲 - KOAN Sound, Fraxtilデータセット)
二つ目のデータセットITGには、難易度が最も高いチャートがない13曲を除いて、難易度ごとに1つのチャートを持つ133曲が含まれています。 2つのデータセットに含まれる曲の総数は比較的少ないですが、全体的に約35時間に相当する35万ステップのアノテーションが含まれています。また、アノテーションには音声データやステップ情報に加えて、曲のタイトル、アーティスト、テンポ情報、難易度などメタデータが含まれています。
提案手法
提案手法のパイプラインは次の構成になります(図1)。
- 音声の特徴量の抽出
- ステップ配置アルゴリズムに入力し、そのフレーム内のステップの確率を推定
- Peak-picking処理を介して、ステップを配置する正確なタイムスタンプを特定
- タイムスタンプのシーケンスをステップ選択のアルゴリズムに入力し、各ステップを選択
以下に、それぞれの詳細について説明いたします。
音声データは44.1kHzでエンコードされています。音声データをPCM(Pulse-code modulation)オーディオにデコードし、短時間フーリエ変換 (short-time Fourier Transform - STFT)を行います。窓サイズは23ms, 46msおよび93msの3種類で10msのストライドになります。窓サイズが短い場合ピッチや音色などの低レベルの特徴を、大きい場合はメロディやリズムなどの高レベルの特徴を表すことができます。さらに、短時間フーリエ変換のスペクトルの次元を80周波数帯域に減らし、対数的にスケーリングすることで人間の知覚をより良く表すことができます。最後に、前の7つのフレームと次の7つのフレームを追加し情報量を増やします。そうすると、最終的な特徴量は15x80x3のテンソルとなり、150msの音声の特徴量の豊かな表現が得られます。
ステップ配置のモデルはフレーム(10ms)内にステップが配置される確率を推定します。従来研究ではCNN(畳み込みニューラルネットワーク)の高い性能が示されています。ステップ配置モデルはこのCNNをさらに性能を上げるために、音声のような時系列データに適したRNN(リカレントニューラルネットワーク)と組み合わせた構造になります(図 5)。
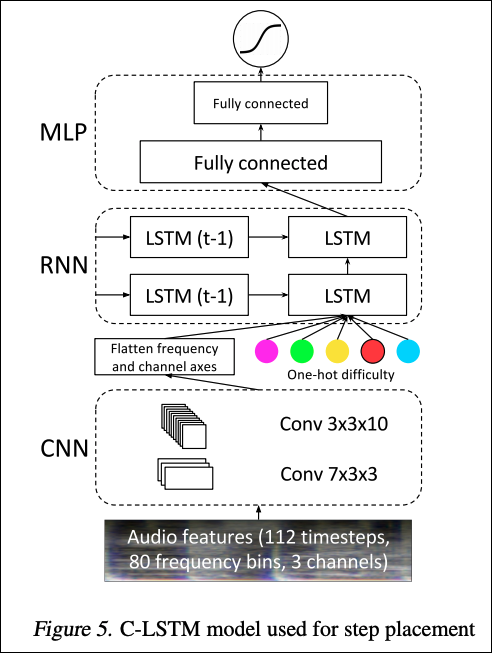
図 5. ステップ配置モデルの構造
CNNで特徴量を抽出した後に難易度のワンホットベクトルが追加され、RNNの入力となります。RNN部分は2層のLSTMから構成されます。
ステップ配置のモデルから各10msフレーム内のステップの確率が推定されます。この予測の一連の確率にHamming window(ハミングウィンドウ)で畳み込み、平滑化および短時間内のダブルピークの発生を抑制することができます(図 6)。
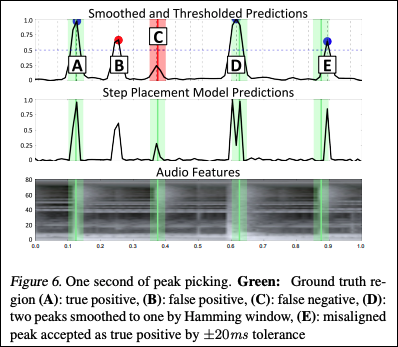
図 6. 1秒の音声データにおけるピークピッキング
次に、一定のしきい値を設定し、確率が高いところをステップ配置として選択します。ピークの数はチャートの難易度によって異なるため、難易度ごとにしきい値を設定しました。
ステップ選択のタスクはシーケンス生成問題として扱うことができます。従来研究では、一貫したテキストを生成する自然言語処理の研究ではRNNの高い性能が示されています。ステップ配置のモデルでは2層のLSTMを使用します。モデルは、トークン(矢印の種類)のシーケンスとリズミカルな特徴量を入力とし、次のトークンを予測します(図 7)。入力トークンのシーケンスは4つのトークン(各トークンがon、off、hold、releaseの4つの状態)の16個の特徴量となります。
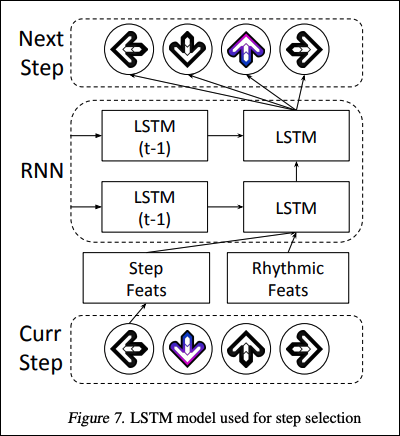
図 7. ステップ選択モデルの構造
リズミカルな特徴量には以下のものが含まれます。
- Δ-timeは、前のステップからの時間と次のステップまでの時間を表す特徴量
- Δ-beatは、前のステップからのビート数および次のステップまでのビート数を表す特徴量
- beat phaseは、現在のステップと一番近い16分音符を表す特徴量
実験
データセット(FraxtilとITG)を学習用、バリデーション用、テスト用にそれぞれ80%、10%、10%で分割します。同じ曲の難易度の異なるチャート間に相関関係があるため、同じ分割に入るようにグループ化しました。
ステップ配置
ベースラインとして以下の3手法を用います。
- LogRegは、ロジスティック回帰による手法
- MLPは、2層の全結合層を含むニューラルネットワークになり、それぞれ256と128個のノードを所持
- CNNは、従来研究で紹介された畳み込みニューラルネットワーク
評価指標にはPPL(perplexity)、AUC、F-scorec、F-scoremがあります。
- AUCは、チャートごとのprecision-recall curveの下領域の平均
- F-scorec、チャートごとの一番高いF-scoreの平均
- F-scorem、全てのチャートのF-scoreの平均
PPLは値が低いほど、AUCおよびF-scorec、F-scoremは値が高いほど高性能のモデルになります。
論文での実験結果を表2に示します。
表 2. ステップ配置の実験結果
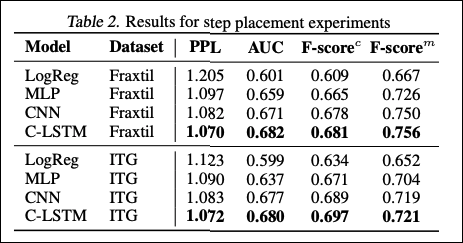
両方のデータセットにおいて、提案した手法が全ての指標で性能が高い結果になりました。特に、難易度が高いチャートに対してFスコアが高くなる傾向にありました。
ステップ選択
ベースライン手法
- KN5は、n-gramモデルの一種で従来研究で実装された5-gramモデル
- MLPは、2層の全結合層を含むニューラルネットワークになり、それぞれ256と128個のノードを所持
- LSTM5は、提案手法のLSTMモデルはセル数が64となりますが、長期的な依存関係の学習を検証するためにセル数が5のLSTMモデル
指標にはPPL(perplexity)とAccuracyがあります。
- Accuracyはトークンの精度
表3に実験結果をまとめます。指標は全てのチャートの平均値になります。
表 3. ステップ配置の実験結果
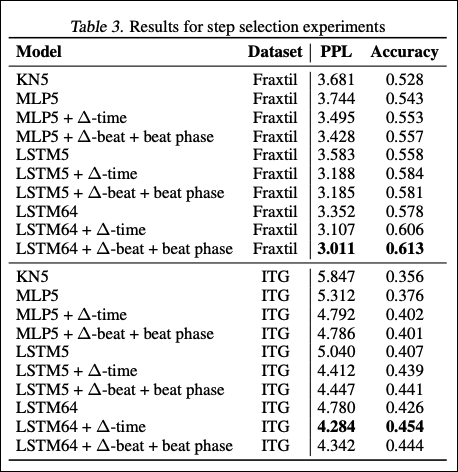
FraxtilデータセットにおいてΔ-beatとbeat phaseの特徴量を用いた場合、性能が一番高くなりました。一方、ITGデータセットにおいてΔ-timeの特徴量を用いた場合、性能が高くなりました。
まとめ
本研究ではディープラーニングによるDDRチャートの作成手法が提案されています。従来研究のCNNモデルを時系列データに適したRNNと組み合わせることで高性能モデルを実装しました。提案手法を検証するために2つのデータセットを作成し、モデルの学習および評価を行い、従来研究のアプローチとの比較を行いました。実験結果はステップ配置とステップ選択の2つのタスクにおいて提案手法が優れた結果となり、DDRチャート作成においてディープラーニングが利用可能なことが示されました。
最後に
今回紹介したステップチャートの作成はKLabの譜面制作支援システムの譜面生成と同様な課題になります。研究課題は同様でありますが、解決アプローチとしてKLabでは画像生成タスクにおいて近年目覚ましい成果をあげている敵対的生成ネットワーク (GAN) を利用しています。モデルの学習にはKLabで蓄積されているリズムアクションゲームの楽曲データおよび譜面データを利用しています。また、モデルの性能を向上させる目的でData Augmentationの手法も研究開発しております。よって、これらの研究成果を複数のタイトルで利用し、多くの人に遊んでもらえれば研究開発の最終的な目的が達成できます。
このブログについて
KLabのゲーム開発・運用で培われた技術や挑戦とそのノウハウを発信します。
おすすめ
合わせて読みたい
このブログについて
KLabのゲーム開発・運用で培われた技術や挑戦とそのノウハウを発信します。