
3D案件における負荷対策について
はじめに
この記事は KLab Creative Advent Calendar 2018 の 21日目の記事になります。
こんにちは。テクニカルアーティストグループ(以下:TAG)のこかろまです。
モバイル端末は日々進化を遂げており、その成長は先日発売されたApple社のiPadProは「Microsoft社のXboxOneSに匹敵するグラフィックス性能」とまで言われるほどです。
モバイルゲームもそれに比例するように高画質・リッチ化が進んでおり、お客様に体験いただく質の向上に取り組むことがKLabのクリエイティブ部の命題ともなっています。
しかしながら、モバイル端末は世界中で生産されているので端末性能の差が激しいです。
そういった端末群がメインプラットフォームであるモバイルゲームにとって「品質を追求したうえでより多くのお客様に遊んでいただくこと」はとても重要です。
今回は私が担当した3D案件においての負荷対策の一例についてお話ししたいと思います。
負荷対策を行うまでの経緯
今回担当した案件は、15000ポリゴンほどのアニメ調のキャラクターが10人前後画面に入り乱れ、ポストエフェクトによる被写界深度やブルームなどの要素を盛り込んだ、演出重視のアクションゲーム。
すでに開発は中盤に差し掛かっており、ある程度アセットの作成指針や仕様、クオリティラインが出来上がったころの参加でした。
アクションゲームの要であるキャラクターモデルも例外ではなく、すでに30体ほどが完成した状態で開発環境に実装されていました。
前段でお話しした通り、より多くのお客様に遊んでいただくためにも「世界でより多く流通していて、性能的に十分な端末を最低動作環境とするターゲット端末」を策定する必要があったため、今回の案件では検討の結果GalaxyS7において30FPSを達成することを目標としました。
見た目の部分が一定のクオリティラインに到達してきたため、「とりあえず現状の処理負荷を計測してみよう!」という動きになりました。
意気揚々と計測したところ、ゲームパート1週目(約2分前後)は30FPSをキープできましたが、長時間プレイすることによって端末が熱を持ちはじめ、2週目から30FPSを割るようになってしまいました。

モバイルゲームにおいて、周回にストレスがたまることはゲームの離脱要因にもつながります。これはマズイと言うことで、対策を行うためのチームを結成し対策を練ることにしました。
開発の方がプロファイラーで負荷計測したところ、開発中のゲームはレンダリング・スキニング・タイムライン処理が高負荷のTOP3を占めていることが分かりました。
レンダリング処理は、シェーダー、演出、ポストエフェクトなど、複数の要因が絡み合って構築されている都合上、手を付けづらいのもあり、モデルデータがそのまま影響を与えるスキニング処理に一旦目を向けることにしました。
スキニングのコストが高い要因として、スキニングインフルエンス数の最大値
(一つの頂点に何本の骨が影響するか)と、ジョイント(骨)数が多いことがあげられます。
改めてデータを検証したところ、以下のことがわかってきました。
- モデルデータはすべて2インフルエンスで作成されていた
- モバイルゲームにおいて、2インフルエンスは頂点数にもよるが現実的
- インフルエンス数が処理負荷に影響を与えていたわけではないと判断
- 髪の毛、衣装などのいわゆる『揺れもの』制御用ジョイント過多
- 表情制御用のジョイント過多
- 本数の制限を決めきれていなかった
- クオリティラインを突破するために、動かしたい箇所を増やして行った結果、いつのまにか想定していた骨数よりも多くなってしまっていた
つまり、今回のモデルデータで負荷対策を行うとするならば、ジョイント数を削減することがスキニングコストを下げることにつながると判断しました。
その中で、揺れもののジョイント本数削減はダイレクトに品質に影響してしまうので、品質を落とさずに負荷を下げることができる箇所である表情の仕組みから着手することにしました。
やったこと
前置きが長くなりましたが、今回負荷対策として行ったことは表情をジョイントベースの
仕組みから、ブレンドシェイプベースの仕組みに構造を変更したことになります。
ここで、ジョイントベース、ブレンドシェイプベースそれぞれのメリット・デメリットについて振り返ろうと思います。
ジョイントベース ... ジョイント(骨)を頂点に紐付け、動かすことで表情制御
【メリット】
- 表情制御するデータ容量はジョイントを制御するアニメーションデータのみなので、ジョイントが共通であればモデルデータが増えても一定使いまわすことが可能
【デメリット】
- 骨を動かして表情を制御するので、現状の骨でクオリティが足らない場合骨を追加する必要がある
- 骨数・端末スペックにもよるが現状のモバイル端末では比較的重い処理
ブレンドシェイプベース ... 表情のメッシュを用意しブレンドすることで表情を制御
【メリット】
- 頂点を増減させなければ自由に形状を調整することができるため、クオリティをアップさせやすい
- 基本、頂点変形を行うのみなので、ジョイントベースに比べると比較的軽い
【デメリット】
- あらかじめMaya等のDCCツールでブレンドしたい表情をセットアップしておく必要があり、ブレンドシェイプしたいメッシュごとに表情分の容量が増える
- 作成したブレンドシェイプ以上の形状にすることはできない
- 表情アニメーションデータの共通化が基本不可能
(※頂点IDや頂点のトポロジーを揃えることで共通化は可能だが今回データでは不可能だった)
どちらの手法も一長一短あります。
モデラーの方が本番モデルをブレンドシェイプ化出来るように手動で対応してくださったので、こちらを使ってジョイントベースのデータと処理負荷を比較してみたところ、すべてのテスト端末において
ブレンドシェイプの方がジョイントベースのデータより高速であることが判明しました。
処理負荷対策の構造として是非とも採択したいところです。
しかしながら、一般的なブレンドシェイプのように頭部モデル全体に対して表情分のブレンドシェイプを設定してしまう場合、同一キャラクターの別メッシュ(例えば、生え際を変更したい等、頂点の増減に影響が出る変更の場合)の際にもブレンドシェイプを用意する必要があり、かつ表情が一つでも増えた場合、すべての頭部モデルに対して追加表情分のブレンドシェイプをマージしなければいけません。
ジョイントベースであれば、ジョイントのアニメーションデータを作成するだけで
表情を追加することができ、容量には大きく影響がありません。
また、アセットとしても頭部モデルデータに手を加える必要もありません。
あらかじめ表情ごとに.meshを作成、ランタイム時に表情ごとの.meshを取得してベースメッシュに対してブレンドシェイプを追加する方法もありますが、ランタイム負荷はロード時間の増大につながるので避ける必要がありました。
とはいえモバイルゲームにおいて過去配信したアセットに表情を追加する等、手を加えることはテストケースの増大、なによりお客様へのデータダウンロードの負担にもつながるので、こちらもなるべく避けたいところです。
どちらもいいとこどりをした手法ができないだろうか...

改めて、頭部のモデルについて振り返ってみます。

上のGIF動画は、色々な表情のイラストを連番にしたものです。
あることに気づきませんか?
上記動画の頭部でアニメーションする範囲は「目の周囲・口の箇所」のみで、
それ以外の部位は動いていないのです。これは、アニメ調である3Dモデルも同様のことが言えそうです。
※リアリスティック系は筋肉の動きを再現するように表情を作ることもあるので3Dモデルが一概にはそうとは言い切れません。
つまり、
- 目、口など、あらかじめジョイントベースで作った表情から動く頂点を計算
- 「動く部分のメッシュ」を切り出して、表情分ブレンドシェイプ化
- それ以外の頂点を「動かないメッシュ」とする
- ゲーム再生時に目、口などの「動く部分のメッシュ」と「動かないメッシュ」を合体させる
とすることで、ブレンドシェイプメッシュを最小限に抑えることができます!

しかも、動かないメッシュ部分は差し替えることができるので、例えば別の髪型を設定する際は生え際の部分のメッシュの流れを変更したい!となっても問題なく対応できます。
さらには動かない部分のメッシュはスキニングしなくて済むため、スキニングコストをさらに削ることもできます。

完全に勝ちました。
実装について簡単にご説明します。
実装
まず、ジョイントベースで作成された表情データを取得します。私はイテレータを多用する都合上PythonAPI 2.0ではなく、Python API 1.0とmaya.cmds、UIにqtを併用しています。
あらかじめ、デフォルトとなる表情の頂点IDと各頂点座標を取得します。
cmds.pointPositionでも取得することは可能ですが、数千、数万ポリゴンを超えてくると永遠と処理に時間がかかってしまうので、基本的にPython APIで取得します。
| 表情名 | フレーム(60FPS) |
|---|---|
| 通常 | 000 |
| あ | 010 |
| い | 030 |
| う | 050 |
| え | 070 |
| お | 090 |
| ん | 110 |
| 微笑み+目閉じ | 130 |
| 微笑み+目閉じ笑い | 150 |
今回表情データは上記のリストのように、それぞれの表情を一つのmaデータの指定フレームごとに作成されていたので、あらかじめ辞書として用意指定表情分のフレームの頂点IDと頂点座標を取得します。
import maya.cmds as cmds
import maya.OpenMaya as om
class ReducedBlendShape(object):
def __init__(self):
self.eye_expression_mesh_name = 'eye_facial'
self.mouth_expression_mesh_name = 'mouth_facial'
self.eye_blend_shape_mesh_name = 'Eye_Around'
self.mouth_blend_shape_mesh_name = 'Mouth'
self.eye_blend_shape_attr_name = 'EyeBlendShape'
self.mouth_blend_shape_attr_name = 'MouthBlendShape'
@staticmethod
def get_selection_mesh_node():
selection_list = om.MSelectionList()
m_node_fn = om.MFnDagNode()
m_dag_path = om.MDagPath()
m_object = om.MObject()
om.MGlobal.getActiveSelectionList(selection_list)
try:
selection_list.getDagPath(0, m_dag_path, m_object)
iter = om.MItSelectionList(selection_list)
while not iter.isDone():
iter.getDagPath(m_dag_path, m_object)
if m_dag_path.hasFn(om.MFn.kMesh):
m_node_fn.setObject(m_dag_path)
return m_dag_path
iter.next()
except ValueError:
pass
# 頂点IDと頂点座標を取得(頂点座標は5桁で丸める)
@staticmethod
def get_vertex_information(dag_path):
'''
:return : dict
'''
m_dag_path = dag_path
m_object = om.MObject()
mesh_fn = om.MFnMesh(m_dag_path)
vtx_iter = om.MItMeshVertex(m_dag_path, m_object)
vtx_dict = {}
while not vtx_iter.isDone():
m_point = vtx_iter.position(om.MSpace.kWorld)
vtx_id = vtx_iter.index()
vtx_position = [round(m_point.x, 5), round(m_point.y, 5), round(m_point.z, 5)]
vtx_dict[vtx_id] = vtx_position
vtx_iter.next()
return vtx_dict
上記で取得した表情を元にあらかじめ取得しておいたデフォルト表情の頂点IDと
各頂点座標を比較し、動く頂点を{頂点ID : 頂点座標の辞書}として追加します。
取得した頂点IDを元にメッシュを分割すると、各パーツごとに分離されたメッシュができます。
@staticmethod
def split_mesh_from_vertex_id(dag_path, vertex_ids):
'''
:return : string[]
'''
# validate
if not vertex_ids and not dag_path:
return
dag_path_name = dag_path.partialPathName()
cmds.select(clear=True)
for vertex_id in vertex_ids:
vertex_attr = dag_path_name + '.vtx[%d]' % vertex_id
cmds.select(vertex_attr, add=True)
face_list = cmds.polyListComponentConversion(fromVertex=True, toFace=True)
cmds.select(face_list, replace=True)
cmds.polyChipOff(ch=True, kft=True, dup=False, off=0)
dag_path.extendToShapeDirectlyBelow(0)
split_meshes = cmds.polySeparate(dag_path_name)
return split_meshes
しかし、ウェイト付けの方法にもよりますが、これでは左目部分、右目部分、口部分、
動かない部分など、それぞれのアイランドごとで分離されてしまいます。
できる限りまとめた方がブレンドシェイプターゲットの最小限化による容量削減、
ゲームエンジン上でのマテリアルコール数の節約に繋がります。
今回のデータはすべてのキャラクターの原点が同一だったので、どのキャラクターも分離されたメッシュ全体の頂点の平均座標を取得することで左目付近、右目付近、口付近、それ以外の動かないメッシュとして部位の特定を行うことができました。
部位の特定後、目付近、口付近、動かないメッシュとしてメッシュ結合、名前を整理します。
次に、整理された分離メッシュでのそれぞれの表情のブレンドシェイプメッシュを作成します。
先ほど取得した表情ごとの動く頂点IDと頂点座標辞書を元に新たに1からメッシュを作成してもいいのですが、ここではメッシュ分離した際のスキニングヒストリが残っているBADノウハウと言いますか、Mayaの仕組みを利用しました。
あえてジョイントでスキニングされた状態のヒストリを残してあげることで、頂点やメッシュが分離されているにもかかわらずそのままジョイントベースのアニメーションを流し込むことで再生することができるので、これを利用します。
cmds.file等でジョイントベースのフェイシャルアニメーションを読み込み、該当の表情データのフレームにcurrentTimeで変更した後、ブレンドシェイプ化したいメッシュをduplicateします。
@staticmethod
def get_duplicate_from_time_mesh(dag_path, time, rename):
# validate
if not dag_path:
return
dag_path_name = dag_path.partialPathName()
cmds.currentTime(time, edit=True)
mesh = cmds.duplicate(dag_path_name)
cmds.rename(mesh, rename)
return mesh
これを表情分繰り返すことで、分離した状態での頂点IDでのブレンドシェイプターゲットメッシュを簡単に作成することができます!
もちろん、最後には不必要ヒストリを削除する必要があるので、表情作成後にヒストリを削除します。今回はスキニングウェイト等のデフォーマーも不必要なので特に考慮することなく、
cmds.delete(dag_nodes, ch=True)
を呼んであげればまるごとヒストリが削除されます。
表情作成後にブレンドシェイプターゲットを設定します。
ブレンドシェイプアトリビュート名がそのままUnityのanimationclipのpropertyNameとなるので、きちんと明示してあげます。
@staticmethod
def set_blend_shape_attrbute(dag_path, expression_mesh_name, blend_shape_attr_name):
# validate
if not dag_path:
return
dag_path_name = dag_path.partialPathName()
expression_meshes_naming = expression_mesh_name + '*'
cmds.select(clear=True)
cmds.select(expression_meshes_naming, add=True)
cmds.select(dag_path_name, add=True)
target_blend_shape_mesh = cmds.ls(sl=True, transforms=True)
cmds.blendShape(target_blend_shape_mesh, name=blend_shape_attr_name)
return
切り出された箇所の頂点の法線はそのままだとばらばらとなってしまっているので、シェーディングによっては継ぎ目がバレてしまったり、法線を使用しているアウトラインシェーダー等に影響が出てしまいます。

そこで、メッシュとメッシュの頂点位置が近似の箇所を取得し、法線を合わせます。
class Normal(object):
def __init__(self):
self.tolerance = 0.05
def tolerance(self):
return self.tolerance
@tolerance.setter
def tolerance(self, value):
self.tolerance = value
return
@staticmethod
def get_vector(x_point, y_point):
delta_x = x_point[0] - y_point[0]
delta_y = x_point[1] - y_point[1]
delta_z = x_point[2] - y_point[2]
vector = math.sqrt(delta_x * delta_x + delta_y * delta_y + delta_z * delta_z)
return vector
def copy_normal(self, object_a, object_b):
# validate
if not object_a and not object_b:
return
object_a_vertex = cmds.polyListComponentConversion(object_a, tv=1)
object_b_vertex = cmds.polyListComponentConversion(object_b, tv=1)
object_a_vertex_expand = cmds.filterExpand(object_a_vertex, sm=31)
object_b_vertex_expand = cmds.filterExpand(object_b_vertex, sm=31)
for object_a_vertex in range(0, len(object_a_vertex_expand)):
object_a_vertex_position = cmds.pointPosition(object_a_vertex_expand[object_a_vertex], w=1)
for object_b_vertex in range(0, len(object_b_vertex_expand)):
object_b_vertex_position = cmds.pointPosition(object_b_vertex_expand[object_b_vertex], w=1)
compare_vector = self.get_vector(object_a_vertex_position, object_b_vertex_position)
if compare_vector > self.tolerance:
continue
normal_value = cmds.polyNormalPerVertex(object_b_vertex_expand[object_b_vertex], q=1, xyz=1)
cmds.polyNormalPerVertex(object_a_vertex_expand[object_a_vertex], x=normal_value[0], y=normal_value[1], z=normal_value[2])
return
完成です!

動くメッシュと動かないメッシュを自動的に切り分けることができました。
手でやると時間のかかってしまいコストパフォーマンスに優れない要件であっても、スクリプトで実装することで現実的に実装可能になるのがスクリプトのよいところだと思います。
結果
ブレンドシェイプベース変更前と変更後を再度プロファイリングしたところ、驚きの結果が出ました!
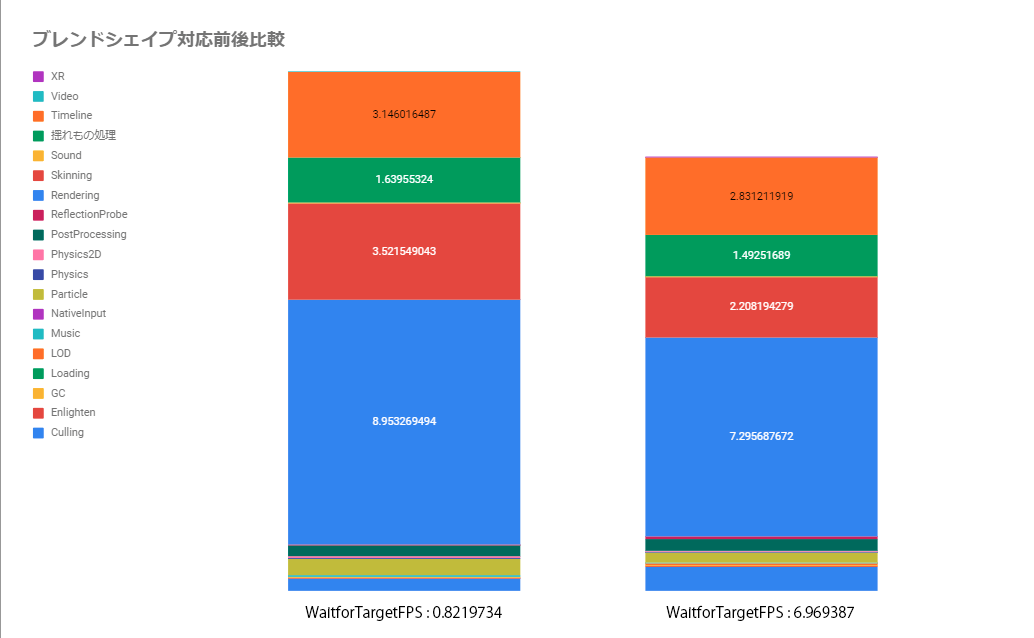
スキニングコストは 中央の赤の箇所ですが、3.521549043 -> 2.208194279 !!
なんと6FPSもの余裕ができ、ゲームプレイを重ねても30FPSで安定するようになりました。
本案件はUnity2018.2.0なのですが、近日リリース予定のUnity2018.3.0ではComputeShaderによるブレンドシェイプのGPU Skinning対応なども盛り込まれており、アップデート後の端末次第でさらなる高速化が期待できそうです。
まとめ
実は、今回実装したデータは表情から動く箇所を抽出した最小限の頂点をブレンドシェイプ対象としていましたが、実装を変更しルートジョイント以外のスキニングウェイト値が入っている頂点を切りだし対象メッシュとするように変更しました。
理由としてはアプリ運営時に表情が増える想定をした際に、現状の表情群では動いていない頂点、ただしスキニングは設定済みの頂点を動かしたくなる可能性が出てくる懸念があり、そうなってしまった時にデータ更新でしか対応できないためです。
なぜ今回上記のような表情ごとの差分での手法を紹介したかと言いますと、上の方が実装が大変だったから
余談ですが、弊社内ではこの動く部分のみブレンドシェイプ化をしたデータを
「バットマン型ブレンドシェイプ」と呼ばれている時期がありました。
切り出された形状がバットマンのマスクのようだったからです。
このページを見てくださった方の何かお役に立てましたら幸いです。
明日のKLab Creative Advent Calendar 2018 の 22日目は、しおりさんです。
よろしくお願いします。
© Unity Technologies Japan/UCL
このブログについて
KLabのクリエイターがゲームを制作・運営で培った技術やノウハウを発信します。
おすすめ
合わせて読みたい
このブログについて
KLabのクリエイターがゲームを制作・運営で培った技術やノウハウを発信します。